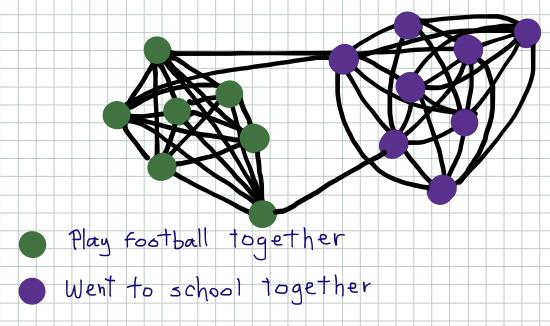
Cut in an undirected graph
提到无向图的最小割问题,首先想到的就是Ford-Fulkerson算法解s-t最小割,通过Edmonds–Karp实现可以在\(O(nm^2)\)时间内解决这个问题(\(n\)为图中的顶点数,\(m\)为图中的边数)。
但是全局最小割和s-t最小割不同,并没有给定的指定的源点s和汇点t,如果通过Ford-Fulkerson算法来解这一问题,则需要枚举汇点t(共\(n-1\)),时间复杂度为\(O\left(n^2m^2\right)\)。
Can we do better?