之前对分布式KV存储关注不多,最近抽时间看了一下Google的Megastore和Wechat的PaxosStore的论文,发现其中很多设计考量的角度都很有趣,值得仔细思考。
Megastore
Megastore相对来说是一个比较老的系统了,是在Spanner大规模运用之前构建在Bigtable之上,支持跨行事务的一套过渡解决方案。
结构
整体上来看,Megastore把和root table中某个root entity相关的所有child table中的行组成一个entity group,并以此作为多副本同步的基本单元。在设计上通过切分entity group,将绝大部分访问限制在entity group内部获得了扩展性的提高,再通过Paxos对entity group做多副本,获得了可用性的提高。
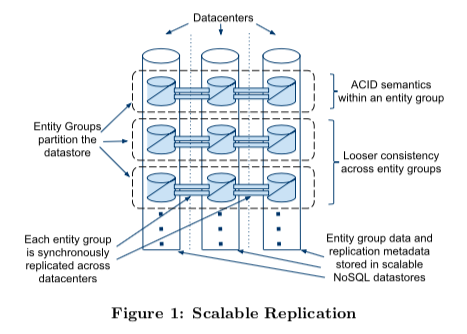
Megastore的多副本结构
并发控制
在事务的并发控制方面,Megastore可以说是比较粗暴的,以entity group为粒度,整个entity group内的事务是完全串行执行的(当然,实现了Serializable隔离级别),读写事务之间是以写在root entity上的log position做为互斥的,同时开启的事务只有一个能够成功写日志到最新的log postition上,其余事务都会失败。这个最新的log position就可以理解为整个entity group的写锁。
对于跨entity group的事务,需要使用两阶段提交,但由于entity group的粒度还是太小了,很容易导致参与者数量过多,并且每个entity group内部使用的都是first-commiter-win的乐观并发控制机制,跨entity group的事务在冲突比较高的场景下极有可能回滚,因此也不推荐使用。
高可用
Megastore的多副本实现是我个人认为最有趣的部分。
首先,Megastore使用了一种可以认为是“简化”的Multi-Paxos实现。在Megastore中,每个log entry都是Basic Paxos,并且在value中额外写入了proposer的信息(比如ip),log entry N-1上决定的value中的proposer被允许在log entry N上跳过prepare阶段,直接使用0作为proposal number来执行accept请求。这个被称为“Fast Write”的优化在无冲突写入的情况下,可以让同一个proposer可以对一连串的log entry省略prepare阶段的开销。这个算法的前提是log必须连续确认,结合上面entity group的并发控制(完全串行)来看这并不是一个问题。
另外,Megastore特别强调使用了非”Master-Based”的方法,以避免当Master宕机后由于lease没有过期导致的服务中断。这一点我个人觉得是设计上的取舍不同,Paxos算法本身并不需要”Master”,也不需要lease,之所以引入lease其实是RSM(复制状态机)上读取请求的一致性需求,试想在RSM上如何确保读请求能够读到最新的数据?lease就是为了给leader提供了这样的保证,让leader可以在lease过期前直接服务读请求,或者像Raft一样为读请求写日志。Megastore的做法也并不神奇,为了不引入lease的问题,Megastore必须时刻知道哪些副本上的数据是最新可读的,因此要求写事务在正常情况下都要等到所有副本日志都同步成功才能提交,或者,将未完成同步的副本状态更新到“coordinator”上,来“赶走”读请求。

Megastore的写路径较长
不难看出,这样的方法并不能说完美,在跨城市的部署情况下等待所有副本同步完成时延较高,并且还引入了coordinator节点的可用性问题。难怪Spanner论文中提到Megastore的写入性能较差。
和Percolator有什么不同?
Google还有另一篇介绍如何Bigtable上解决了多行事务的论文,叫做Percolator,不过,两者面对的场景不同,所以方案有很大不同。
Percolator并不解决可用性问题,提出了一种利用单行事务来实现多行事务的方法,其基本思路还是在多行上做两阶段提交。Megastore面对的是OLTP场景,行之间的两阶段提交显得太过昂贵了,因此首先将行partition到entity group粒度,减少两阶段提交的使用,然后再解决entity group的可用性问题。
PaxosStore
PaxosStore是WeChat的分布式KV存储,论文中提到其设计受了Megastore设计比较大的影响,整体看下来也确实如此。
PaxosStore中的Paxos实现和Megastore如出一辙,同样使用了”Fast Write”的方法,日志格式如下图,每个Entry都是一个Basic-Paxos,决议中的Proposer ID可以跳过下一个PaxosLog的prepare阶段。

PaxosLog
并且PaxosStore也采用了非”Master-Based”的方法,和Megastore不同的是,为了避免coordinator的可用性问题,PaxosStore选择让读请求询问所有副本来确定本地数据是可读的(论文后面提到一些优化,但原理还是一样的)。
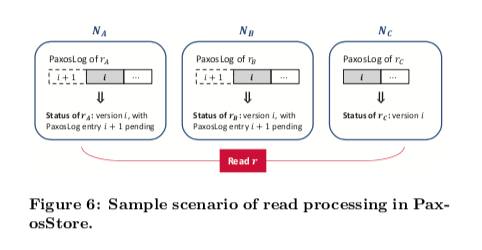
读操作需要读多个副本
另外,因为是单纯的KV实现,没有多行事务的需求,实际上PaxosStore中并发控制的粒度更小,仅仅是一个value的修改,实际上这样的需求根本不需要记redo log(回顾数据库中为什么需要log来保证原子性,是因为多个page的修改没有办法保证原子的刷盘,Megastore中是因为Bigtable无法保证entity group中的多行修改是原子的),因此PaxosStore中的PaxosLog实际上是一种修改历史,既然是历史,那么回收策略也就更加简单了(相比于数据库的checkpoint),想保留几个版本都可以,论文中提到仅留了两个PaxosLog,一个是最新数据,一个是正在进行的修改。为了减少IO,数据存储干脆直接引用最新的PaxosLog中的value,也是一种特别的优化。
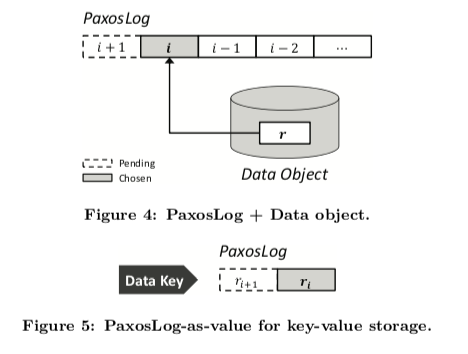
减少一次I/O
参考资料
[1] Baker J, Bond C, Corbett J C, et al. Megastore: Providing scalable, highly available storage for interactive services[C]//CIDR. 2011, 11: 223-234.
[2] Zheng J, Lin Q, Xu J, et al. PaxosStore: high-availability storage made practical in WeChat[J]. Proceedings of the VLDB Endowment, 2017, 10(12): 1730-1741.
[3] Peng D, Dabek F. Large-scale Incremental Processing Using Distributed Transactions and Notifications[C]//OSDI. 2010, 10: 1-15.