因为项目关系,接触学习了大名鼎鼎的Python网络编程框架Twised,Twisted是以高性能为目标的异步(event-driven)网络编程框架。

Twisted book
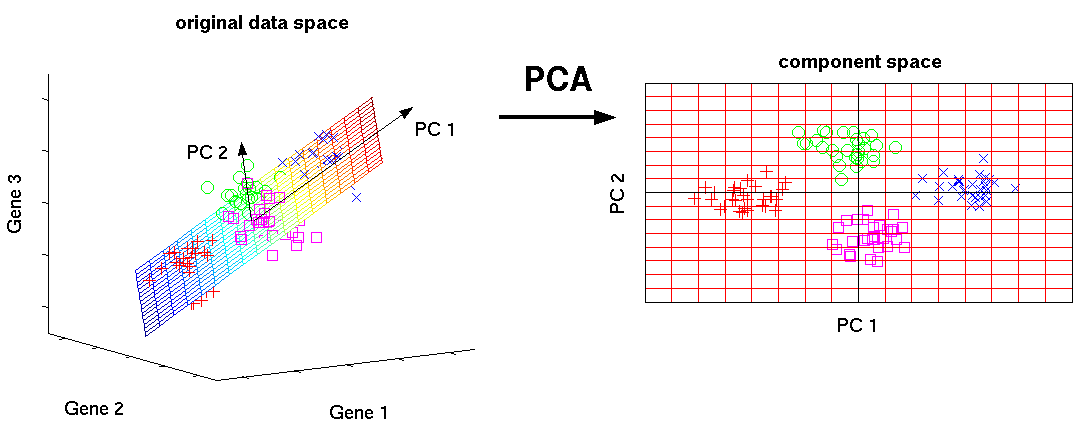
图中是Twisted官方推荐的学习书籍的封面,我觉得封面设计的非常贴切:Twisted就是很多Python(蟒蛇)纠缠在一起。
很多人说Twisted太复杂了,不易于使用,而我并不这么认为。虽然代码流程和朴素的代码流程大相径庭,但复杂性源自于异步编程的思想,而Twisted通过优秀的封装已经极大了减轻了我们的工作量。如果你之前没有接触过异步编程模型,我认为从Twisted入手不失为一个很好的选择。
学习Twisted的最好方式就是阅读Twisted的最新官方指南,有详尽的解释和代码示例,网络上其他的教程都是浪费时间(包括本文,前提是如果本文算得上是教程的话…)。