Paxos被公认是难度很高的分布式共识算法,一方面是体现在理解其算法正确性的难度上,而另一方,体现在工程实现的复杂度上。在将Paxos算法运用在工程实践的过程会遇到各种各样的问题,本文要探讨的“幽灵复现”问题,就是其中一例。
什么是“幽灵复现”
据我所知,所谓的“幽灵复现”问题是Oceanbase团队在实现Multi-Paxos过程中自己提出的,并随着郁白的一篇知名博文的传播被大家所知晓。这里先简单介绍一下问题场景:
使用有Leader lease(避免活锁,leader读写提供线性一致性)的Multi-Paxos来实现复制状态机,刚开始A是Leader,客户端执行操作写1-10号日志,1-5号日志形成多数派,但是6-10号日志没有同步到其他副本,客户端超时。
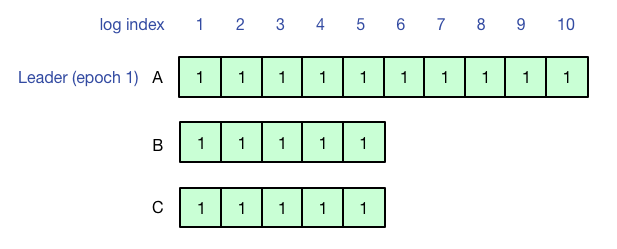
之后A宕机,B成为新的Leader,由于联系不到A,B和C作为多数派从6号日志开始工作,此时查询不到先前客户端在A上写的结果(6-10号日志没有同步成功)。
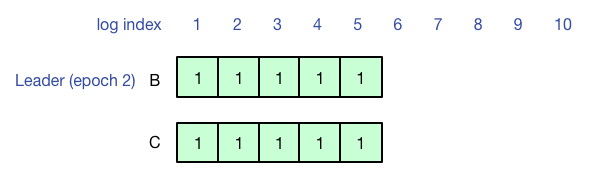
最后A再次成为Leader,并成功把之前的6-10号日志同步到多数派,此时再查询,就可以查询到之前客户端写入的结果了。
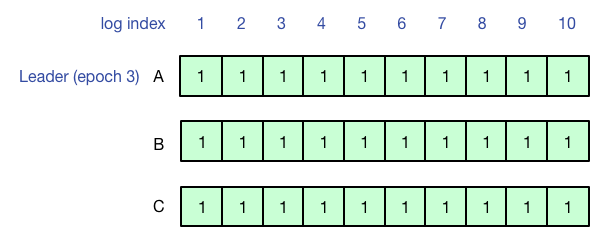
问题出在哪?
“幽灵复现”这个现象在工程实践中毫无疑问是一个需要注意的问题,但我认为这个问题并不是分布式共识(Consensus)本身的问题,而是上层逻辑导致的一致性(Consistency)问题。
让我们重温Paxos算法的正确性条件:
- 只有被提出(propose)的值才可能被最终选定(chosen)
- 只有一个值会被选定(chosen)
- 进程只会获知到已经确认被选定(chosen)的值
在前面描述的问题场景中,虽然存在“幽灵复现”的Paxos instance,但实际上这些instance在“复现”之前从来没有达成共识(chosen),也就是说,不论查询这些日志是“消失”还是“复现”,都没有违背分布式共识算法的safety属性。
那么是复制状态机的问题么?也不是。按照上例分析并发操作的一致性表现:刚开始客户端在A上写操作w1超时,但并没有返回客户端执行成功,之后在B上执行读操作r2看不到w1的执行结果,说明r2的生效时间排在了w1前面,最后在A上发起的读操作r3看到了w1的执行结果,说明r3的生效时间在w1之后,这并没有违背线性一致性的要求。
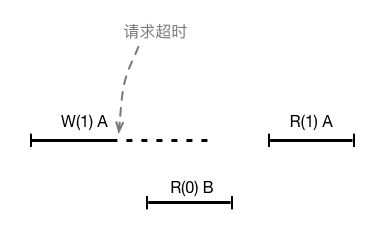
“幽灵复现”其实是在使用Multi-Paxos来同步数据库redo log的场景下产生的问题,郁白的文章中没有介绍全部的背景,所以让读者有些难以理解了。Oceanbase是一个关系型数据库系统,使用Multi-Paxos来同步数据库的redo log,使用的是WAL(Write Ahead Logging),即保证在持久化数据修改前,对应的redo log要先持久化完成。
基于关系数据库的场景,我们重新解释前面的例子。
刚开始A是Leader,客户端发起事务trx1,先显式对数据x加锁(for update)并收到数据库响应成功,再修改数据x为1,但在redo log同步到多数派之前宕机。之后B当选为Leader,客户端发起事务trx2查询x(for update),读出x为0(意味着没有读到行锁),因此客户端认为trx1的结果是失败回滚。最后A再次成为Leader并完成redo log的同步,此时再客户端发起事务trx3查询x,读出x为1,trx1的结果又变成了成功提交。
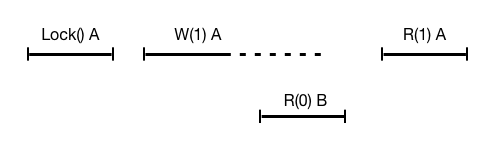
显然,这个执行结果违背了线性一致性的要求,并且这样的行为会导致数据库非常难以使用。
所以,问题的原因在于关系型数据库redo log的同步模式和复制状态机的日志同步模式是不同的,复制状态机在日志同步成功后才会应用日志修改状态机,这样保证了切主后状态机一定不会回退。但关系型数据库的WAL实际上是先修改“状态”后持久化redo log的,所以才导致切主后行锁丢失,引发了问题。
交错Leader
文章开头的例子和郁白原文中例子略有不同,原文中在B成为新的Leader后重写了6号和20号日志,A再次成为Leader后同步了7-10号日志,这个实际上是被我们称为“交错Leader”的问题,即虽然每个Paxos instance都没有违背共识,但在数据库场景中使用redo log的上层逻辑来看,日志却变成了没有意义的:如果1-10号日志是同一个事务的日志,达成共识的日志序列中6号日志却被修改了。
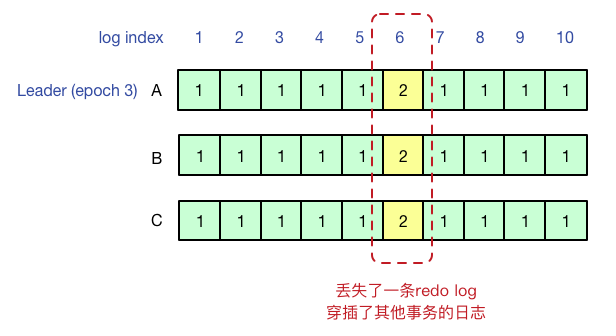
“交错Leader”和“幽灵复现”问题都可以通过提高EpochId,写StartWorking日志过滤的方法解决。
参考资料
- 《架构师需要了解的Paxos原理、历程及实战》 李凯