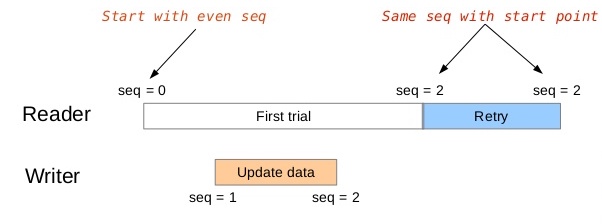
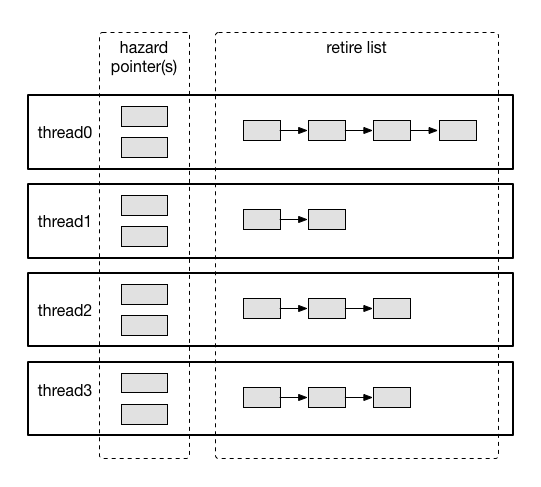
#include <pthread.h>
#include <stdlib.h>
#include <stdio.h>
#include <algorithm>
using namespace std;
static const int64_t MAX_THREAD_NUM = 128;
static int64_t n = 0;
static int64_t loop_count = 0;
#pragma pack (1)
struct data
{
int32_t pad[15];
int64_t v;
};
#pragma pack ()
static data value __attribute__((aligned(64)));
static int64_t counter[MAX_THREAD_NUM];
void worker(int *cnt)
{
for (int64_t i = 0; i < loop_count; ++i) {
const int64_t t = value.v;
if (t != 0L && t != ~0L) {
*cnt += 1;
}
value.v = ~t;
asm volatile("" ::: "memory");
}
}
int main(int argc, char *argv[])
{
pthread_t threads[MAX_THREAD_NUM];
/* Check arguments to program*/
if(argc != 3) {
fprintf(stderr, "USAGE: %s <threads> <loopcount>\n", argv[0]);
exit(1);
}
/* Parse argument */
n = min(atol(argv[1]), MAX_THREAD_NUM);
loop_count = atol(argv[2]); /* Don't bother with format checking */
/* Start the threads */
for (int64_t i = 0L; i < n; ++i) {
pthread_create(&threads[i], NULL, (void* (*)(void*))worker, &counter[i]);
}
int64_t count = 0L;
for (int64_t i = 0L; i < n; ++i) {
pthread_join(threads[i], NULL);
count += counter[i];
}
printf("data size: %lu\n", sizeof(value));
printf("data addr: %lX\n", (unsigned long)&value.v);
printf("final: %016lX\n", value.v);
return 0;
}