但凡是接触过数据库的同学一定不会对事务(transaction)的概念感到陌生,我第一次接触事务的概念还是在本科的数据库课本上,了解了事务并发控制概念,但在之后多年不严肃的前后台开发经历中,我几乎从来没有考虑过数据库的“隔离级别”,这让我产生了一种”数据库如此好用,世界如此美好“的幻觉…直到现在从事了数据库内核的开发工作,才对事务的并发控制有了一点点认真的理解。
这篇文章即是我对事务并发控制的一些粗浅的理解。
事务并发执行的正确性
一般来说,教科书中都是类似的描述事务:”数据库并发控制的基本单元“,事务管理器和执行引擎需要和并发控制协作,来保证数据库中事务的执行是”正确“的。数据库中事务并发控制的正确性,也就是我们常说的Isolation。
PS:并发事务的正确性除了我们最常讨论的Isolation之外还有Consistency和Recoverable,限于篇幅,本文仅讨论Isolation。
串行调度
最容易理解的正确性保证就是串行调度(serial schedule),即不允许事务并发,所有事务排队,一个接着一个串行执行,其正确性是显然的,同时,执行效率低也是显然的。
可串行化调度
为了提高数据库的执行效率,显然我们需要并发的执行各个事务,如果存在调度S,对于数据库的任何状态,其执行结果完全等价于另一个串行调度S’,称这样的调度S为可串行化调度(serializable schedule)。
对比串行调度,等价的可串行化调度可就多的多了,并发度大幅提升,但我们又该如何实现并发控制才能校验出一个调度是可串行化的?总不能先按串行调度执行,再对比结果吧?
我们需要一个更加易于验证的条件,并且保证满足这个条件的调度是一定是可串行化的。
冲突可串行化调度
冲突可串行化(conflict serializable)就是这样的条件,按照两个不同的事务对数据库中的同一元素(需要特别注意,这里的元素不等同于一行数据,可能为一个条件范围,也可能是一张表)的操作组合,定义出三种冲突(conflict):
- Read-Write conflict
- Write-Read conflict
- Write-Write conflict
所谓冲突,指的是调度中的一对动作,满足:如果它们的顺序交换,则涉及到的事务中至少有一个的行为会改变。如果调度S通过交换调度中的非冲突动作可以变换为串行调度,这样的调度S称为冲突可串行化调度(conflict serializable schedule)。
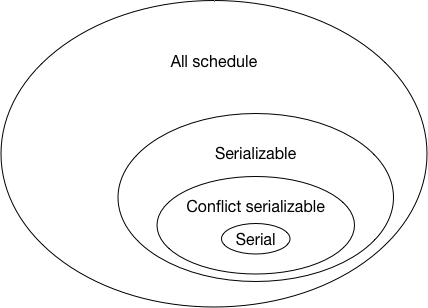
冲突可串行化调度是可串行化调度的子集,它的意义在于相对于可串行化,冲突可串行化是一个更加容易验证的条件,因此更加适合作为事务并发控制的实现依据。事实上,现在隔离级别中常说的可串行化(serializable),其实是就是指冲突可串行化(conflict serializable)。
实现无关
按照一般教科书的套路,写到这里接着的,一定是优先图和Strict 2PL这些用来验证冲突可串行化的实现方案,这里我就偷懒不写了:-)
我想要强调的是一个非常非常非常容易被误解的点:调度中的冲突不是用来解决的,并不是说这三个操作是冲突的,我们就不能允许冲突的事务并发发生!我们要做到的,只是要求这些有冲突的并发事务按照冲突关系不组成环即可。
因为在数据库发展的早期阶段,大部分的数据库实现都依赖于锁,在锁的实现上,为了达到上述要求,会拒绝冲突的事务并发执行,这样的思维根深蒂固,导致我们非常容易陷入这样的陷阱。
举个简单的例子:
\(H_{serializable}:\text{W1[A]W2[A]W3[A]W1[B]W2[B]W3[B]W1[C]W2[C]W3[C] c2 c1 c3}\)
上面的历史中,三个事务对三个数据元素的写操作都是并发发生的,但是显然这个历史是可串行化的,其结果等价于T1T2T3串行执行。可以看到,冲突可串行化的定义是完全实现无关的,是非常准确和理想的定义。
向性能低头
可串行化固然会让用户感到安心,但是由于可串行化调度的验证方式往往伴随着大量的阻塞等待(比如2PL),难以达到很高的事务并发执行性能,为了提供更好的并发执行性能,数据库不得不放宽调度的验证,允许更多非可串行化的调度被执行。
显然,多个并发的事务执行结果可能会不再等价于任何一种串行执行的结果,也就是说,事务不再是“隔离”的,事务之间相互产生了影响,导致结果出现了错误。
没错,从隔离的角度来看,这样的事务并发执行结果就是错误的,但却是为了提高性能不得不付出的代价。为了规范用户使用,数据库需要给用户做出保证:什么样的错误会发生,而什么样的错误不会发生,这些不同的保证,就是数据库的隔离级别。
PS:隔离级别和分布式系统中的Consistency类似,都是一种向性能的妥协。Linearizability虽好,可性能代价太高,才产生了种种正确性保证更弱,但并发执行性能更好的Consistency定义。
隔离级别
隔离级别的含义极其混乱,这得从隔离级别的发展讲起。
ANSI隔离级别
ANSI SQL-92标准中基于事务并发执行过程中可能出现的三种导致数据错误的现象(Phenomena)定义了一套隔离级别1:
1) P1 (“Dirty read”): SQL-transaction T1 modifies a row. SQL-
transaction T2 then reads that row before T1 performs a COMMIT.
If T1 then performs a ROLLBACK, T2 will have read a row that was
never committed and that may thus be considered to have never
existed.2) P2 (“Non-repeatable read”): SQL-transaction T1 reads a row. SQL-
transaction T2 then modifies or deletes that row and performs
a COMMIT. If T1 then attempts to reread the row, it may receive
the modified value or discover that the row has been deleted.3) P3 (“Phantom”): SQL-transaction T1 reads the set of rows N
that satisfy some. SQL-transaction T2 then
executes SQL-statements that generate one or more rows that
satisfy theused by SQL-transaction T1. If
SQL-transaction T1 then repeats the initial read with the same
, it obtains a different collection of rows.
标准中按照这三种现象的容忍程度不同,定义出了4个不同的隔离级别,其中P1、P2、P3都不能出现的隔离级别即为最高的隔离级别Serializable:
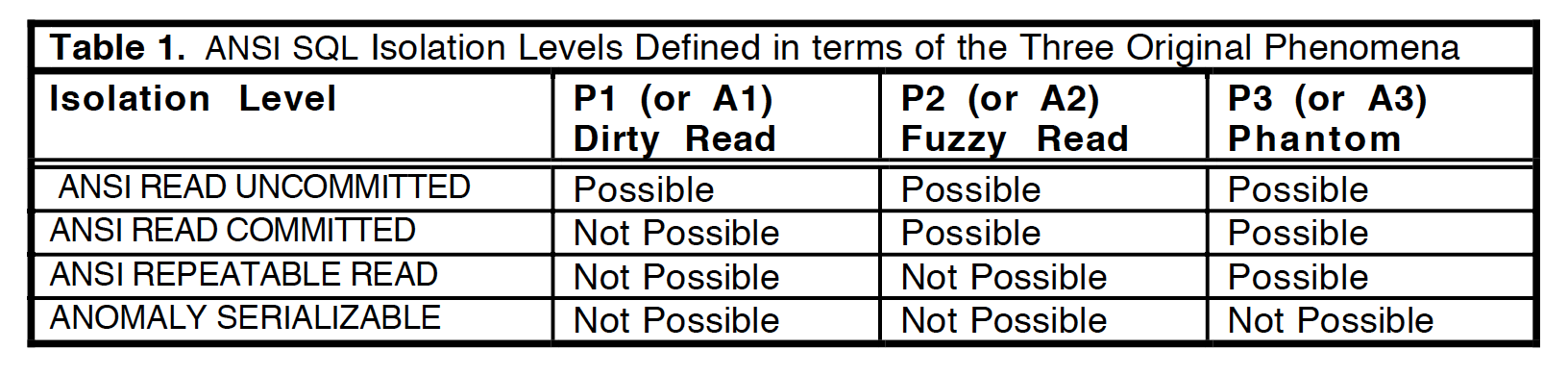
ANSI隔离级别试图定义出一套实现无关的隔离级别,但这个尝试失败了,这一次失败的尝试,可以说是业界隔离级别实现的混乱之源…
A Critique of ANSI SQL Isolation Levels
95年的这篇论文2指出了ANSI隔离级别的问题,首先,是用英文文字描述隔离级别的不严谨,容易产生歧义,按照ANSI文档描述,将P1、P2、P3描述为异常(anomaly):
A1: w1[x]…r2[x]…(a1 and c2 in either order) (Dirty Read)
A2: r1[x]…w2[x]…c2…r1[x]…c1 (Fuzzy or Non-Repeatable Read)
A3: r1[P]…w2[y in P]…c2….r1[P]…c1 (Phantom)
接着指出这样的描述太过于狭义,不能表达ANSI隔离级别想要实现的本意,即使排除了全部三个现象(Phenomena),仍然有可能出现其他的数据错误,并不能达到Serializable。因此拓展出广义的定义:
P0: w1[x]…w2[x]…(c1 or a1) (Dirty Write)
P1: w1[x]…r2[x]…(c1 or a1) (Dirty Read)
P2: r1[x]…w2[x]…(c1 or a1) (Fuzzy or Non-Repeatable Read)
P3: r1[P]…w2[y in P]…(c1 or a1) (Phantom)
并且用广义的定义重新描述了ANSI隔离级别:
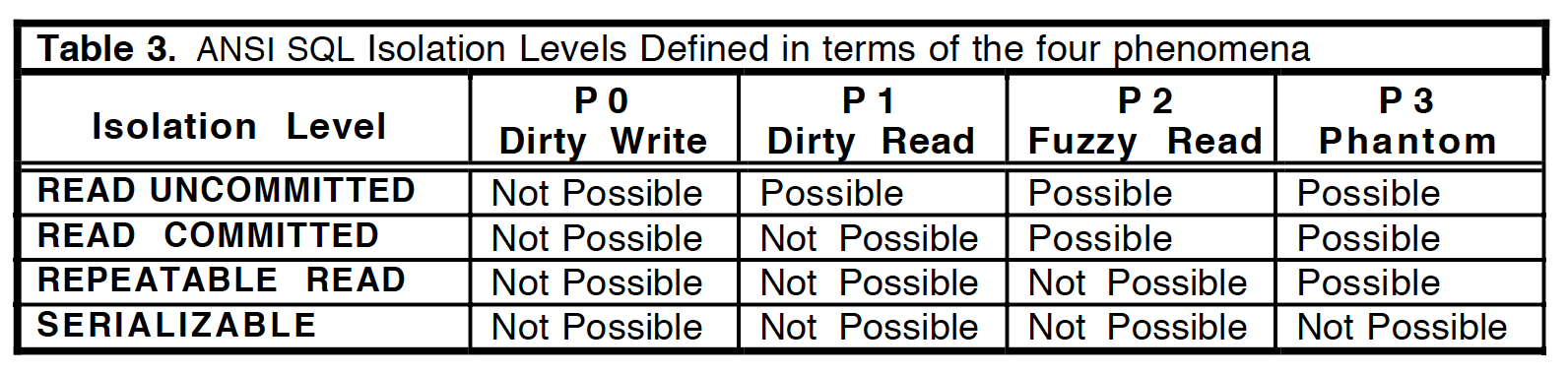
然后指出了ANSI隔离级别最大的问题:基于这4个现象定义的隔离级别和锁实现的隔离级别完全等价!也就是说,ANSI隔离级别仅仅考虑了2PL实现中可能会出现的现象(Phenomena),因此定义出的隔离级别并不能做到实现无关。为了定义出更加全面的隔离级别,论文对ANSI隔离级别做出补充,分析并增加了两种锁实现中的可能异常(P4C和P4)和两种多版本并发控制实现中可能出现的异常(A5A和A5B),最后将所有这些异常组合在一起,定义出了新的隔离级别标准:
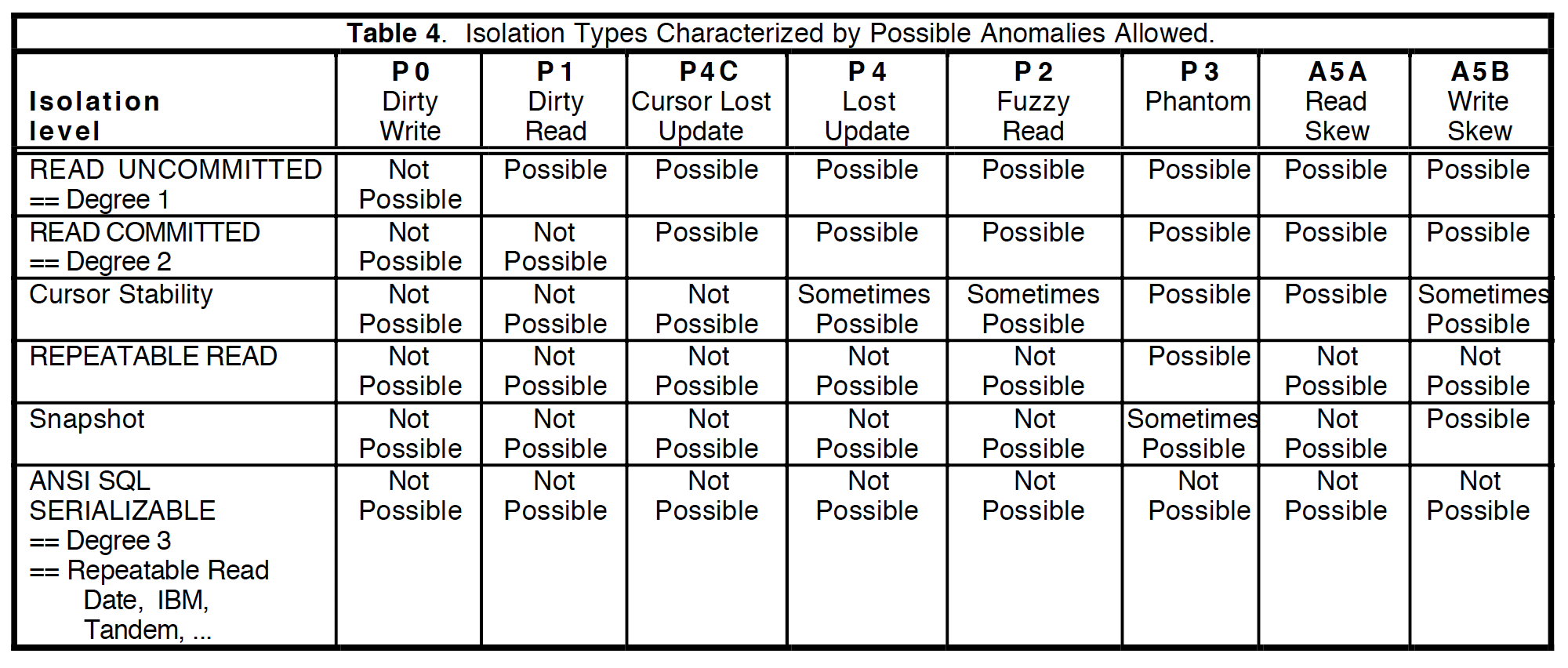
这篇论文已经很好的指出了ANSI隔离级别存在的问题:没有做到实现无关,然而确没有很好的解决这个问题。虽然通过广义的定义消除了歧义,并且考虑了多版本实现的异常,但是排除掉这些依据特定实现定义的异常对于其他实现来说限制“过于严格”,会同时排除很多并发度更好的调度。
Generalized Isolation Level Definitions
到了2000年,Ayda终结了隔离级别的讨论,提出了完全实现无关的隔离级别定义3。
这篇论文“重新定义”了ANSI隔离级别,但是和上面提到的论文不同,Ayda没有继续走老路,去分析并发执行的事务产生的异常,而是回归到了事务的本质,通过事务之间的依赖关系,来定义完全实现无关的隔离级别。
论文的核心在于观察事务之间的依赖关系,将其归纳为三种:

如果一个调度中事务间的依赖关系没有形成环,则为Serializable。论文据此重新揣度了ANSI隔离级别想要做到的目的,用事务间依赖的方法重新描述了ANSI隔离级别:

新的定义相比于berenson广义的定义,在排除了不合法的调度的同时做到了实现无关。比如拿PL-1来举例,其对应于Dirty Write,在使用锁的实现中,事务的写操作要加写锁,则必然保证了事务之间的写写冲突是无环的,但是反之并不成立:写写冲突不成环并不要求事务修改元素后之后(提交前)不能允许其他事务再次修改元素。
\(H_{serializable}:\text{W1[A]W2[A]W3[A]W1[B]W2[B]W3[B]W1[C]W2[C]W3[C] c2 c1 c3}\)
再翻出上面提到过的例子,如果排除掉P0,则这样的调度是不允许的,但是PL-1则允许,可见PL-1的定义更加准确。
在Ayda的博士论文4中,更是用事务依赖关系的理论完整的描述了各类隔离级别:
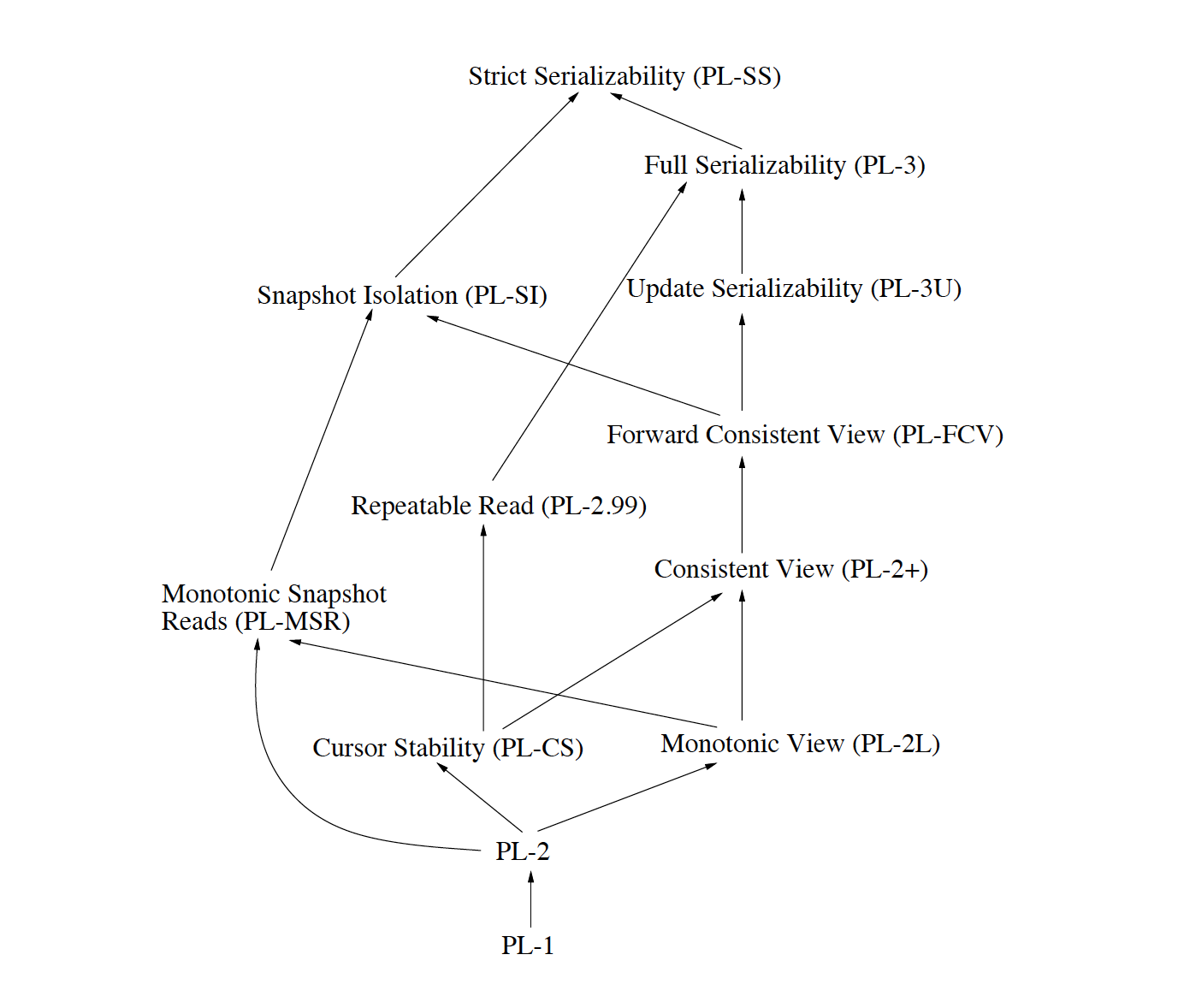
事实标准
正如上文看到的,从事务隔离到隔离级别,学术界经过了数十年的讨论,终于找到了一个如何描述事务隔离性的满意答案。但是,工业界真正实现的数据库,却是另外一幅景象…
由于真正实现无关的隔离级别标准常年缺席,ANSI隔离级别定义又模糊不清,各个数据库对隔离级别的实现真是五花八门,乱七八糟…
正如Peter Bailis5所说,现实中的数据库系统没有几个实现了真正的Serializable,即使他们做了这样的保证:
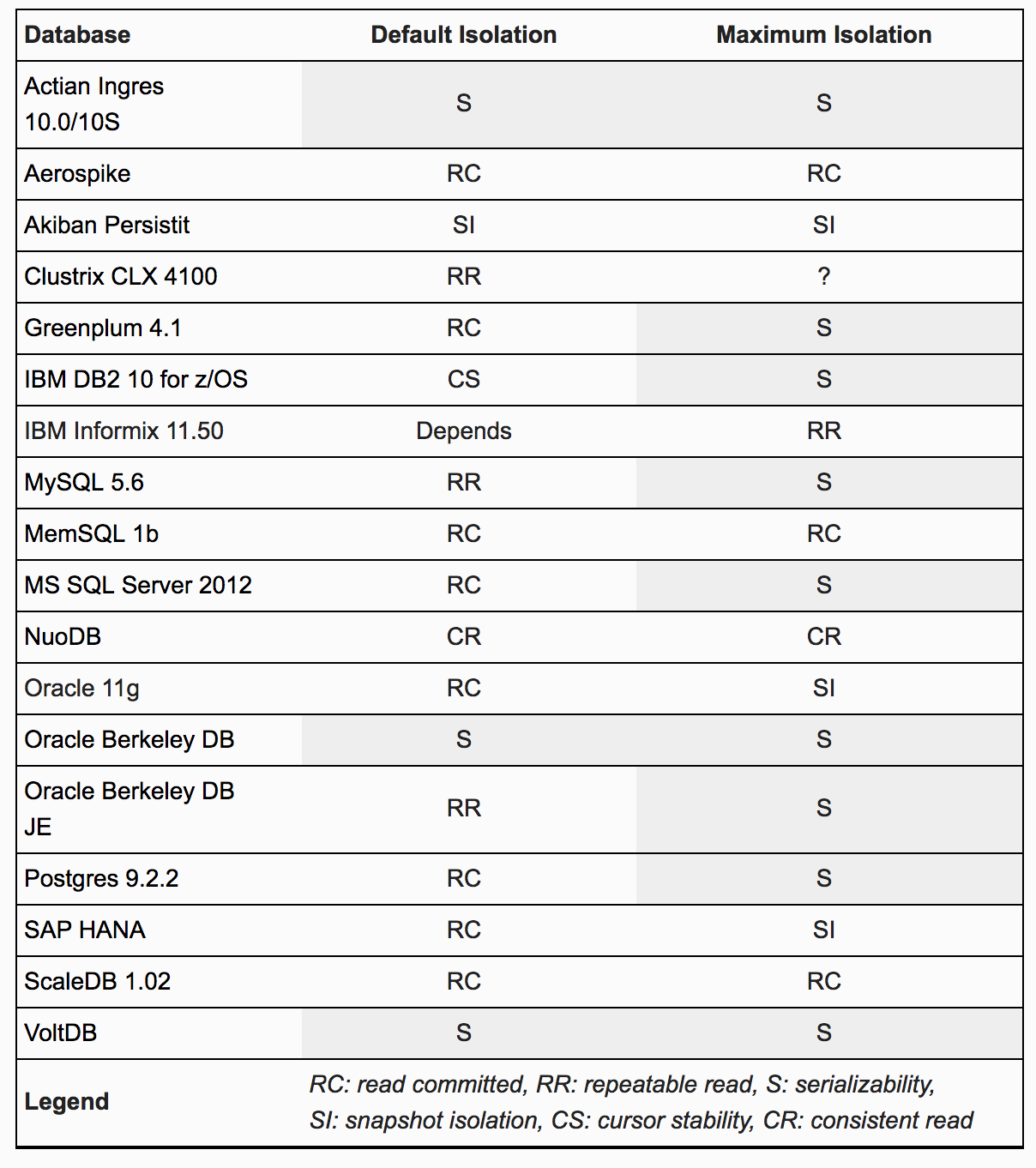
Oracle
就拿大厂Oracle来说,在隔离级别的实现上也并没有多讲究。Oracle 11g提供的两种隔离级别:Read Commited和Serializable。然而,最高的”Serializable“隔离级别并不是真正的可串行化调度(Serializable),而是Snapshot Isolation。
也就是说,即使用户设置到所谓的”Serializable”隔离级别,仍然可能发生Write skew异常。你可能会好奇,是什么给了Oracle勇气,把这样的实现称之为“Serializable”?答案就是SQL92标准制定的ANSI隔离级别,Snapshot Isolation排除了A1,A2,A3三种异常。
MySQL
再说说另一个我们比较熟悉的数据库MySQL(innodb引擎),实现的更是混乱…MySQL提供了4个隔离级别,由低到高依次是:Read Uncommited、Read Commited、Repeatable Read以及Serializable。
好的一点是MySQL的Serializable使用的是strict-2PL的实现,确实做到了名副其实的Serializable。但是Repeatable Read的行为就让人完全摸不到头脑了。
例如这个测试6中提到的,在初始状态如下的数据库中:
|
1 2 |
create table test (id int primary key, value int) engine=innodb; insert into test (id, value) values (1, 10), (2, 20); |
会有Lost update:
|
1 2 3 4 5 6 7 8 |
set session transaction isolation level repeatable read; begin; -- T1 set session transaction isolation level repeatable read; begin; -- T2 select * from test where id = 1; -- T1 select * from test where id = 1; -- T2 update test set value = 11 where id = 1; -- T1 update test set value = 11 where id = 1; -- T2, BLOCKS commit; -- T1 commit; -- T2 |
会有Read skew:
|
1 2 3 4 5 6 7 8 9 10 |
set session transaction isolation level repeatable read; begin; -- T1 set session transaction isolation level repeatable read; begin; -- T2 select * from test where id = 1; -- T1. Shows 1 => 10 select * from test; -- T2 update test set value = 12 where id = 1; -- T2 update test set value = 18 where id = 2; -- T2 commit; -- T2 delete from test where value = 20; -- T1. Doesn't delete anything select * from test where id = 2; -- T1. Shows 2 => 20 commit; -- T1 |
会有Write skew:
|
1 2 3 4 5 6 7 8 |
set session transaction isolation level repeatable read; begin; -- T1 set session transaction isolation level repeatable read; begin; -- T2 select * from test where id in (1,2); -- T1 select * from test where id in (1,2); -- T2 update test set value = 11 where id = 1; -- T1 update test set value = 21 where id = 2; -- T2 commit; -- T1 commit; -- T2 |
这是哪门子的Repeatable Read?这还是SQL92标准中的ANSI隔离级别定义搞的鬼,虽然有上面种种异常,但是却排除了SQL-92标准中文字描述版的P1和P2(注意,这里连A1和A2都不是),所以说是Repeatable Read。倒也心安理得了。
要想理解MySQL的行为,就必须了解内部对事务操作的实现。MySQL中的并发控制混合使用了MVCC和锁的方式,在Repeatable Read隔离级别下,只在每个事务开始时获取一次快照,之后的读语句都使用这个快照来做读取,但是写语句和加锁的读语句又不使用这个快照,而是用锁的方式用最新的快照操作的,所以产生了各种奇葩行为。
如何生存?
现实中隔离级别的实现如此混乱,导致数据库的用户完全没有办法按照一个通用的标准来确定自己的事务行为是否安全,而必须按照底层数据库的实现行为作为判断依据。
从数据库行业来看,这实在让人心痛,但是从数据库厂商的角度来看,这又何尝不是一种壁垒?而且是一种非常好用的护城河,来防止用户的流失。
WTF,我只想存个数据
如此复杂的隔离级别,足以让任何想要”简单写入一条记录“的程序员头大了,也难怪为什么NoSQL会大行其道。然而在现在的背景下再看,实际上抛弃Serializable的风险是巨大的,Google的研究方向(Percolator、Megastore以及Spanner)也证明了Infra的发展方向仍然是提供”正确“的基础设施,对数据库而言,Serializable就是”正确“的最高标准(有关外部一致性的话题留待之后再写)。
那性能该怎么办呢?
作为一个Infra的从业者,我很崇尚Spanner的做法:直接向上层应用提供最高的正确性保证,运用各种硬件、软件技术提高性能和横向拓展能力,达到上层应用的性能要求。但是用户需求毕竟是不同的,也不是所有用户都像Google一样,有用不完的机器资源,所以现阶段来看,上层应用仍然需要了解这些混乱的规则。
自动驾驶一定是未来,但现在我们还是一样要考驾照的。
Update:数据库是否一定要实现Serializable呢?Oracle为什么不实现真正的Serializable?一个可能的原因是用户的实际需求并不大。首先是出现异常的概率比较低,另一点是因为真正对数据异常敏感的用户也并不会完全依赖数据库的隔离性,上层会有多套的数据正确性验证。
参考资料
- SQL92 ↩
- Berenson H, Bernstein P, Gray J, et al. A critique of ANSI SQL isolation levels[C]//ACM SIGMOD Record. ACM, 1995, 24(2): 1-10. ↩
- Adya A, Liskov B, O’Neil P. Generalized isolation level definitions[C]//Proceedings of 16th International Conference on Data Engineering (Cat. No. 00CB37073). IEEE, 2000: 67-78. ↩
- Adya A. Weak consistency: a generalized theory and optimistic implementations for distributed transactions[J]. 1999. ↩
- When is “ACID” ACID? Rarely. ↩
- Testing MySQL transaction isolation levels ↩