Nanos是JYY大神为南大计算机系操作系统课程专门设计的实验用操作系统。出于对操作系统的好奇和对JYY大神的敬仰,我又再次踏上了DIY玩具内核的道路。和本科时候不同,这次希望能对操作系统有更深的理解,而不是仅仅局限于完成实验,也希望能留下一些笔记作为积淀。这是第一篇note,从分析Nanos的bootloader开始再好不过了。
Nanos的框架代码都可以在github上找到(点我),为了方便起见,一份打包的仅包含bootloader的代码在这里。
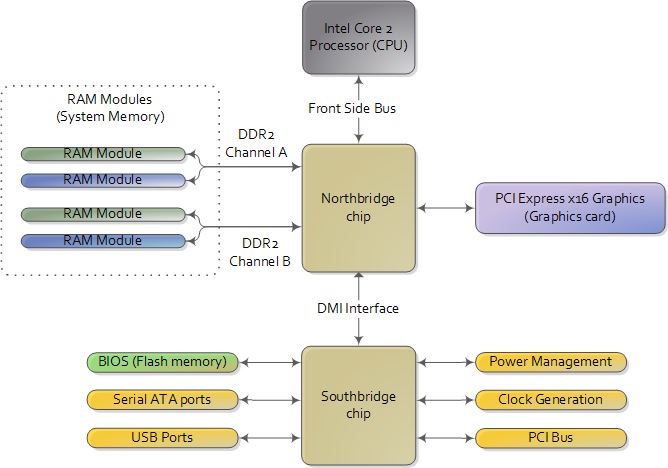
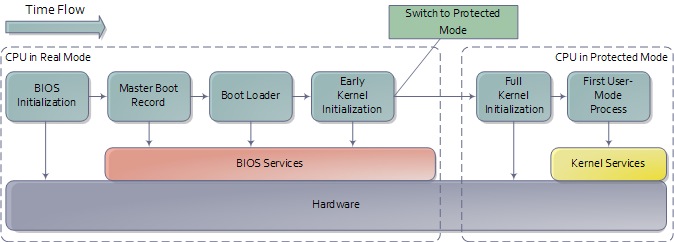
正如之前提到的,在计算机的启动过程中当完成了POST之后,BIOS会从可启动磁盘中读出头512个字节(MBR)并将其载入内存地址0x7c00的位置并开始执行,MBR中的代码通常被称为bootloader,负责将操作系统内核载入到内存中。在Nanos中,bootloader极其简单,仅由MBR中的512字节组成(即仅包含stage 1),麻雀虽小五脏俱全,Nanos的bootloader完成了bootloader所需要做的所有基本任务:为操作系统内核设置运行环境、载入内核到内存、跳转到内核开始执行。
下面具体分析一下Nanos的bootloader是如何完成的。首先看一下bootloader的源文件目录结构:
|
1 2 3 4 5 6 7 |
. ├── Makefile ├── asm.h ├── boot.h ├── genboot.pl ├── main.c └── start.S |