Sequential lock,简称seq lock,是一种有点特殊的“读写锁”,Linux内核从2.6版本开始引入,是一种非常简单轻量保护共享数据读写的方法。
基本原理
Sequential lock的原理非常简单,其核心就是通过维护一个序号(sequence)来避免读者(Reader)读到错误的数据,而写者(Writer)在加锁和解锁的过程中递增序号,多个写者之间需要借助于额外的互斥锁来保证互斥关系。
具体来讲,序号初始化为0,读者和写者的流程如下:
- 写者开始修改临界区中的数据时,首先获取写者间互斥锁,然后递增序号(奇数),开始修改数据,修改数据完成后会再次递增序号(偶数),然后释放写者间互斥锁。
- 对读者来说,在修改数据的过程中读者可能会读到错误的数据,但读者在读数据前后会分别获取一次序号,对两次获取的序号进行比较,如果不相同则说明在读取过程中有写者进入了临界区,需要重试;如果序号相同但是是奇数,说明读者开始读取到结束读取的这段时间写者占有了临界区,同样也需要重试。
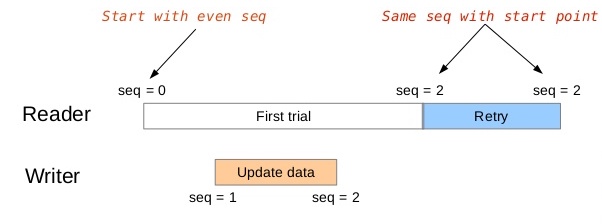
SeqLock时序示意
看个例子就明白了,如上图所示,是不是非常简洁明了。
适用场景
明白了seq lock的原理之后再来思考一下这个锁究竟特别在哪里,又适用于什么样的场景。
如果你熟悉并发控制的几种常用机制,你就会发现seq lock实际上是一种乐观并发控制(OCC),也称为乐观锁。为什么乐观呢?因为像这样不阻塞读者执行,当发生冲突时读者重试的并发控制策略是建立在冲突发生频率较低这样的乐观假设之上的,试想如果冲突频率真的很高,势必会造成读者大量的重试,其效率还不如普通的互斥锁来的好。
所以说,seq lock适合于用来保护小的临界区(比较短,避免冲突),且尤其适合读多写少的场景。例如Linux内核中用seq lock来保护64位jiffies的读写,因为在某些体系结构上无法保证64位读写的原子性。
另外从读写锁的角度分析,seq lock中读者不会阻塞写者,也就是说只要没有别的写者,写者可以直接获取seq lock而不需要等待读者,这样的好处在于写者的阻塞很少。但是必须要注意的是,seq lock又不是一种通用的读写锁,正是因为读者不会阻塞写者,所有写者的修改仍会被读者看到(即使会失败重试),所以写者不能有类似于内存释放的操作,否则会导致程序出错。
正确性
seq lock的正确性很容易理解,不过在多核并发的环境下还是得多说两句。下图所示是一个写者和一个读者的执行流程,如果执行正确不能够出现读出的a和b不等于v1的情况。

SeqLock机器指令
我们知道,在多核环境中CPU之间由于独立cache的作用,看到的数据并不是实时同步的,(在我之前的文章中介绍过多核并发编程的一些基本知识,如果感兴趣可以看看),那么这里就会产生一个有趣的问题:会不存在这样一种情况,读者所在的核没有及时看到写者对seq的修改,导致读到了错误的a和b?
当然这种论述是错误的,原因在于,在多核并发编程中,我们并不能依赖于绝对时间来分析程序运行,因为多核间数据并不存在绝对时间上的同步,这个问题最后还是要回归到内存模型上。比如说,考虑Sequential Consistency的内存模型上,由于不允许写乱序,所以如果没有读到写者对seq的第一次修改,是不可能读到写者对x和y的修改的,也就是说,虽然读者在绝对时间上发生在写者之后,但在逻辑时间上发生在写者之前。由于这两个过程并没有因果关系,所以在并发过程中这样的顺序是完全正常的。
更进一步分析,seq lock甚至不需要Sequential Consistency这么强的内存模型保证,仅要求不存在Store-Store乱序和Load-Load乱序,x86体系结构保证这一点,所以在x86体系上实现seq lock不需要使用任何内存屏障指令,十分高效。
实践
纸上得来终觉浅,绝知此事要躬行。C++代码实现seq lock(老样子,只支持x86体系结构):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
#ifndef _SEQLOCK_H_ #define _SEQLOCK_H_ #include "lock.h" class SeqLock { public: SeqLock(BaseLock &lock) : lock_(lock), seq_(0) {}; virtual ~SeqLock() {} SeqLock(const SeqLock&) = delete; SeqLock &operator=(const SeqLock&) = delete; int write_lock() { int ret = lock_.lock(); seq_++; asm volatile("" ::: "memory"); return ret; } int write_unlock() { asm volatile("" ::: "memory"); seq_++; int ret = lock_.unlock(); return ret; } uint64_t read_begin() { uint64_t seq = seq_; asm volatile("" ::: "memory"); return seq; } bool read_retry(uint64_t seq) { asm volatile("" ::: "memory"); if (seq_ != seq) { return true; } return seq & 1; } private: BaseLock &lock_; uint64_t seq_; }; #endif /* _SEQLOCK_H_ */ |
代码很短,seq lock中包含了一个用来做写者互斥的锁,可以使用之前的文章中的描述的任意一种均可。
另外还有一点值得注意的地方是在代码中使用了的几处编译器屏障,这个是在和编译器优化战斗,因为这样的实现编译器优化会将这几个函数做inline处理,而一旦inline之后又会和实际的读写指令做重排。
seq lock如何使用呢?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
static TiketLock tiket_lock; static SeqLock seq_lock(tiket_lock); void writter(void) { seq_lock.write_lock(); // modify critical region seq_lock.write_unlock(); } void reader(void) { uint64_t seq; do { seq = seq_lock.read_begin(); // read critical region } while (seq_lock.read_retry(seq)); } |
是不是非常简单好用,总体来说,对于读多写少的小临界区,seq lock是一个非常实用的编程技术。