从上篇文章到现在,已经有半年多的时间没有写过什么了,时间真是匆匆而过,感觉从上次写博客到现在似乎也就是一眨眼的功夫。
回顾我这大半年,完全可以用四个字概括:“不务正业”,先是跟着曼昆的书学习了微观、宏观经济学的基础知识,恶补了一下个人理财的基础理论(很有意思,但依然挡不住我买的基金嗷嗷跌),然后又入坑了摄影(其实就是买个微单瞎拍瞎修)。至于个人的技术提升方面就显得捉襟见肘了,先是跟着斯坦福CS145、CS245两门课程复习了一下数据库方面的知识,然后就在分布式系统的泥沼中挣扎到了现在…可能唯一一件值得纪念的事情就是去年年底抱大牛大腿参加某司举办的hackathon,过程中学到了一点Golang的皮毛,最后搞了个apple watch耍(队友大牛依然表示对结果不太满意…),另外出于对tby大牛的仰慕,又补习了一下前端开发技能,然并卵,已经又忘光了…
一不小心写了一大段流水账,回归主题。之前花了大概两个多月时间从头琢磨分布式系统,研一时候修这门课完全是白学了,本来学的就不好,两年过去基本也不剩什么了。翻了两本最出名的教材,看了一些高校的课程安排和slides,总算感觉自己有点“上道”了~
这篇文章主要总结一下我个人认为是整个分布式系统中最为重要的问题(没有之一):分布式共识(Consensus)。

达成共识
PS:我在学习过程中是以《分布式系统:概念与设计》1这本书作为基础的,在下文中如果没有特别指明,所提书中内容均指该书。
写在前面
老实说,以我现在对分布式系统粗浅的理解,很难将这个问题总结清楚,因此文中免不了会有些写不明白甚至错误的地方,先留个笔记,待以后有了更加深入的理解再回来修改吧。
分布式系统模型
想说明白分布式共识问题,首先还是得说说分布式系统中的基础模型,我们在设计和思考分布式算法时,首先需要思考的一点就是算法运行的环境是什么,算法运行中需要处理什么样的问题,一般来说从以下三个方面来考虑:
- 分布式系统中进程(节点)会发生什么样的故障?。最为常用的两种故障模型是故障-停止(Fail-stop)和随机故障(Byzantine),在故障-停止模型中当进程发生故障后简单的停止运行,相对的,随机故障又称为拜占庭故障,意指发生故障的进程会像不忠的拜占庭将军一样,产生无法预料的响应结果。故障-停止是随机故障的一种特殊形式,因此,能够容忍随机故障的算法也能够容忍故障-停止。
-
分布式系统的网络传输时延特性是什么样的?在分布式系统中,进程间通过传递消息进行通信,按照消息在网络中传递时间是否有上限,可以将分布式系统分为同步模型(Synchronous model)和异步模型(Asynchronous model),在同步分布式系统中消息传递时间的上限是已知的,而在异步分布式系统中消息可能在任何时间送达。因此在同步分布式系统中,由于消息传递时间的上限已知,则可以根据超时来检测进程故障(非拜占庭故障),大大简化了分布式算法的设计,但遗憾的是,大部分实际的分布式系统往往是异步的,比如互联网就是异步分布式系统,如果为异步分布式系统中设计分布式算法,必须意识到消息可能延迟任意长的时间到达。
-
分布式系统消息传递的可靠性如何?在分布式系统中传递的消息有可能出现丢失、乱序甚至重复送达的情况,算法是否需要容忍这些情况(网络分区就是一种常见的需要加以考虑的现象)?或者,是否可以使用更加可靠的传输协议(比如TCP)来简化算法的设计(Zookeeper2中使用的原子组播协议Zab3就是一个例子)。
在整个设计和思考分布式算法的过程中,都要基于同样的系统模型来进行,并对分布式算法的正确性进行证明。通常来讲,一个正确的分布式算法需要满足两条性质:
- Safety:具备Safety性质的算法保证坏的事情绝对不会发生,例如对于满足Safety性质的分布式选主(Leader election)算法,绝对不会出现一个以上进程被选为Leader的情况。
- Liveness:具备Liveness性质的算法保证好的事情终将发生,即算法在有限的时间内可以结束。
综上,一个正确的分布式算法可以在指定的分布式系统模型中保证Safety和Liveness属性。
分布式共识(Consensus)
分布式共识问题,简单说,就是在一个或多个进程提议了一个值应当是什么后,使系统中所有进程对这个值达成一致意见。
这样的协定问题在分布式系统中很常用,比如说选主(Leader election)问题中所有进程对Leader达成一致;互斥(Mutual exclusion)问题中对于哪个进程进入临界区达成一致;原子组播(Atomic broadcast)中进程对消息传递(delivery)顺序达成一致。对于这些问题有一些特定的算法,但是,分布式共识问题试图探讨这些问题的一个更一般的形式,如果能够解决分布式共识问题,则以上的问题都可以得以解决。
分布式共识问题的定义如下图所示:
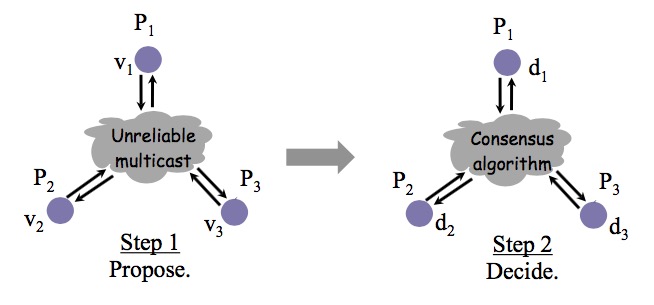
分布式共识问题
为了达到共识,每个进程都提出自己的提议(propose),最终通过共识算法,所有正确运行的进程决定(decide)相同的值。
共识算法的正确性要求是在运行中满足以下条件:
- 终止性(Liveness):所有正确进程最后都能完成决定。
- 协定性(Safety):所有正确进程决定相同的值。
- 完整性(Integrity):如果正确的进程都提议同一个值,那么所有正确进程最终决定该值。
接下来让我们结合系统模型来思考共识问题。
如果在一个不出现故障的系统中,很容易可以构造出一个符合要求的共识算法:每个进程都将自己的提议通过可靠组播(Reliable broadcast)(见书15.4.2节)发送给其他进程,当进程收到所有成员的提议后,取所有提议中出现最多的值作为最终决定即可。
如果在存在故障的同步系统中,书中15.5.2节给出了一种解法,不是本文重点,因此不做过多讨论。
而如果是在存在故障的异步系统中,共识问题是否有可用的解法呢?著名的FLP不可能性证明4告诉我们:没有任何算法可以在存在任何故障的异步系统中确保达到共识,FLP的证明过于庞大,本文不做展开,但其意义是非常重要的,正如之前说的,大部分实际的分布式系统都是异步的,FLP不可能性证明阻止了无数分布式系统设计者把时间浪费在寻找一个完美的异步系统共识算法上,而更应该去使用一个不那么完美却有实际意义的解法。
正如FLP不可能性证明所述,不存在算法可以“确保”达到共识,但我们可以设计出有较大概率可以达到共识的算法。绕过不可能性结论的办法是考虑部分同步系统,利用故障屏蔽、故障检测器或随机化手段避开异步系统模型(详见书15.5.4节),构造出可接受的共识算法,在后文中会重点关注几个异步系统中共识问题的著名工作,并解释它们是如何做到的。
共识与多副本状态机(Replicated state machines)
分布式系统中对共识问题的直接应用常常是在多副本状态机(不太确定这个翻译对不对)的场景中出现的。多副本状态机是指多台机器具有完全相同的状态,并且运行有完全相同的确定性状态机。通过使用这样的状态机,可以解决很多分布式系统中的容错问题,因为多副本状态机通常可以容忍\(\lfloor \frac{N}{2}\rfloor\)进程故障,且所有正常运行的副本都完全一致,所以,可以使用多副本状态机来实现需要避免单点故障的组件,如集中式的选主或是互斥算法中的协调者(coordinator),如图所示:

高可用“单点”的集中式架构
集中式的选主或互斥算法逻辑简单,但最大的问题是协调者的单点故障问题,通过采用多副本状态机来实现协调者实现了高可用的“单点”,回避了单点故障。Google的Chubby服务5和类似的开源服务Zookeeper就是这样的例子。
虽然有很多不同的多副本状态机实现,但其基本实现模式是类似的:状态机的每个副本上都保存有完全相同的操作日志,保证所有副本状态机按照相同的顺序执行操作,这样由于状态机是确定性的,则一定会得到相同的状态,如下图:
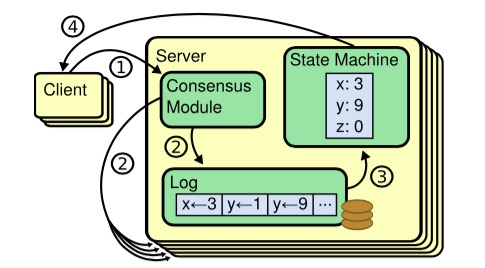
多副本状态机
共识算法的作用就是在这样的场景中保证所有副本状态机上的操作日志具有完全相同的顺序,具体来讲:如果状态机的任何一个副本在本地状态机上执行了一个操作,则绝对不会有别的副本在操作序列相同位置执行一个不同的操作。
接下来,我将对三个我认为非常有代表性的分布式共识算法的工作进行简要介绍,分别是Viewstamped Replication6、Raft7和大名鼎鼎的Paxos算法8,前两个工作本身就是基于多副本状态机的场景完成的,而Paxos算法是作为独立的分布式共识算法提出,并给出了使用该算法实现多副本状态机的范例。
Viewstamped Replication
Viewstamp Replication(以下简称VR)最初被提出是作为数据库中的一部分工作,2012年作为单独的分布式共识算法再次发表。
系统模型
VR算法适用于允许故障-停止的异步系统中,并且VR不要求可靠的消息传递,即VR可以容忍消息丢失、延迟、乱序以及重复。
容错
在一个总共有\(2f+1\)个进程的VR服务中,VR可以容忍最多不超过\(f\)个进程同时发生故障。
原理介绍
从整体上来看,正常运行中的VR副本中一个作为primary,其余副本都作为backup,正如上文所说的,Replicated state machine最关键的问题在于让所有副本状态机按照相同的顺序执行命令,VR中primary副本决定命令的顺序,所有其他的backup副本仅仅接受primary所决定好的顺序。当primary出现故障时,VR执行一个称为view change的过程,在VR中每个view中都有且仅有一个固定的primary,通过执行view change,可以使系统进入下一个view,并选出新的primary取代故障的旧primary副本。
当primary没有发生故障时,VR在一个稳定的view中运行,副本之间通过消息通信,每个消息中都包含了自己当前所处的view-number,仅当收到的消息包含和自己所知吻合的view-number时副本才会处理该消息,如果收到来自旧view的消息,副本简单丢弃该消息,而如果收到更新的view的消息,则副本知道自己落后了,这时需要执行一套特殊的state transfer过程来赶上系统的最新状态。在正常运行中,VR按以下过程执行用户请求:
- client向primary发出请求\(\langle \text{REQUEST } op, c, s\rangle\),其中\(op\)代表需要运行的操作,\(c\)代表client-id,\(s\)代表对于每个client单调递增的request-number。
- primary接收到请求后,会对比收到的request-number和本地记录中该client最近的一次请求,如果新请求不比之前本地记录的请求更新,则拒绝执行该请求,并将之前请求的应答再次返回给client。(每个client同时只能发出一个请求)
- 否则,primary为接收到的请求确定op-number(在view中递增),将该请求添加到本地log中,并用它来更新本地记录中该client的最新请求。然后,primary向所有backup副本发送消息\(\langle \text{PREPARE }v, m, n, k\rangle\),\(v\)是当前的view-number,\(m\)是client发出的请求消息,\(n\)是op-number,\(k\)是commit-number,代表最近的已提交op-number。
- backup收到PREPARE消息后,严格按照顺序处理所有PREPARE消息(和第2步中primary定序结合,相当于构造了全序组播),当该请求的所有前置请求都处理过后,backup副本与primary一样,递增本地op-number、将请求添加到本地log、更新本地对该client的请求记录,最后向primary回复\(\langle\text{PREPAREOK }v, n, i\rangle\)来确认准备完成。
- primary在收到超过\(f\)个来自不同backup的PREPAREOK消息后,对该消息(及之前的所有消息,如果有)执行提交操作:执行client提交的操作,并递增commit-number,最后向client返回应答\(\langle \text{REPLY }v, s, x\rangle\),\(x\)是操作的执行结果,同时primary会将该结果保存在本地,用于防止client故障产生的重复请求(见2)
- primary可以通过PREPARE消息或\(\langle \text{COMMIT }v, k\rangle\)消息通知backup已确认提交的请求。
- 当backup副本收到提交确认消息后,如果该消息已经在本地log中(有可能有落后的副本),则它执行操作、递增commit-number,然后更新本地client请求结果。
这个处理过程如下图所示:
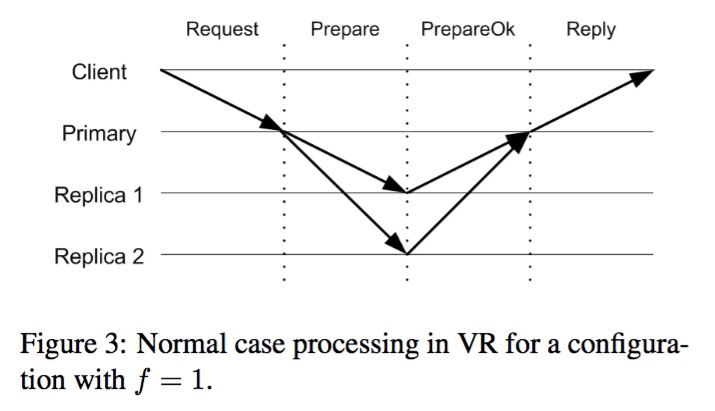
VR正常执行流程
另外,在整个过程中,在没有收到回复时发送方会重复发送消息,以此来对抗可能出现的消息丢失。在VR中只有primary副本可以响应client请求,backup对client请求仅仅是简单的丢弃,如果primary发生了变化,当请求超时后client会向所有副本发送请求以找到新的primary。
如果primary故障,backup就无法收到来自primary的PREPARE和COMMIT(当没有请求是被周期发送,相当于心跳的作用)消息,当触发一个超时后,backup认为primary发生了故障,此时进入了view change阶段,如下:
- 对于副本\(i\),当它发现primary发生了故障(超时)或着收到了来自其他副本的STARTVIEWCHANGE或DOVIEWCHANGE消息,进入view-change状态,它将递增view-number,并且向其他副本发出\(\langle \text{STARTVIEWCHANGE }v, i\rangle\)消息。
- 当副本\(i\)收到来自超过\(f\)个不同副本的吻合它view-number的STARTVIEWCHANGE消息后,它向新的primary副本(VR中选主过程非常简单,所有进程根据IP地址排序获得编号,在每次view change过程中按顺序轮流当primary)发送\(\langle \text{DOVIEWCHANGE }v, l, v’,n ,k ,i\rangle\),\(l\)是它的日志,\(v’\)是它转为view change状态之前的view-number。
- 当新的primary副本收到超过\(f+1\)个来自不同副本的DOVIEWCHANGE消息后,它将自己的view-number修改为消息中携带的值,并选择具有最大的\(v’\)的消息中的\(l\)作为新的log,如果多条消息具有同样的\(v’\),则选择具有最大\(n\)的那个。同时,它将op-number设置为log中尾部请求的序号,将commit-number设置为收到所有消息中最大的。然后将自身状态修改回normal,并向其他副本发送\(\langle \text{STARTVIEW }v, l, n, k\rangle\)以通知他们view change完成。
- 新的primary开始正常响应client的请求,并且同时执行任何之前没有执行完的命令(根据新获得的log)。
- 其他副本在收到STARTVIEW消息后,根据消息的内容修改本地状态和log,执行本地没有提交的操作(由于该副本有落后),并将自身状态修改回normal,另外,如果log中包含未提交的操作(当旧primary还没来得及向其他副本确认提交成功就故障了),则向新primary发送\(\langle \text{PREPAREOK }v, n, i\rangle\)消息。
到这里已经完成了VR算法核心流程的叙述:包括正常状态下的执行和primary副本故障后的view change过程,VR算法还包括了故障进程恢复协议以及动态修改副本配置的Reconfiguration协议,限于篇幅和精力,就不再展开叙述了。
正确性
那么VR算法是正确的么?前文中描述过了共识算法正确性的标准,那么对于VR来说,其共识算法需要保证所有状态机副本以相同的顺序执行操作。
我们分两部分来讨论VR算法的正确性。首先,在正常运行过程中(无primary故障)VR算法显然是正确的,primary决定了统一的操作顺序并将其传播到backup副本上,因此在primary发生故障时的view change协议必须可以保障整体VR算法的正确性。
从Safety的角度来讲,view change必须保证每一个在先前view中已经提交的操作必须能够传递到新的view中,并且处于操作序列中完全相同的位置。理解这个正确性的关键在于注意到VR算法中的两个细节:primary只有在超过\(f+1\)个副本已经收到某操作的前提下才会提交该操作,而在view change过程中,新的primary必须收到来自超过\(f+1\)个副本的log才能开始工作。由于VR最多只容忍\(f\)个副本同时故障,则必然有至少一个了解该操作的副本向新的primary提交了自己的log。
另一个对Safety非常非常关键的点在于:副本一旦进入view-change状态,就不会再响应任何来自旧view的PREPARE消息。这是因为VR算法应用于异步系统,当primary出现超时并不代表primary真正故障了,有可能它只是运行缓慢或者网络延迟严重,随后有可能会出现延时到达的PREPARE消息,这样的消息是非常致命的,为了保证DOVIEWCHANGE消息中包含了所有的已提交操作,必须保证屏蔽掉旧view中的primary。这种方式实际上相当于使用故障检测器屏蔽超时进程,将异步系统改造成为了半同步系统,绕过了FLP不可能性结论。
至于Liveness,论文证明了view change满足liveness,这也是我的一个疑问,不是说异步系统不能确保达到共识么(后文中的两个算法在Liveness上都有些缺陷)…
Raft
Raft是近些年比较新的关于分布式共识的工作,其最大的优点在于易于理解、易于实现(相对于之前的统治者Paxos,这是极大的优势),这也极大的推动了它的发展,现在很多新的分布式项目都转而使用Raft作为核心,例如etcd。这里有一个Raft可交互的在线展示,对理解Raft很有帮助。
系统模型
Raft同样运行在允许故障-停止的异步系统中,并且不要求可靠的消息传递,及可以容忍消息丢失、延迟、乱序以及重复。
容错
在一个总共有\(2f+1\)个进程的Raft部署中,可以容忍最多不超过\(f\)个进程同时发生故障。
原理介绍
Raft的整体思路与VR基本相似,在Raft中有存在唯一的leader,由leader全权负责响应用户的请求,leader对用户请求的操作确定顺序并传递给其他follower,并在可以提交操作时通知其他follower。如果leader发生了故障,则执行leader election过程选出新的leader。
从上述整体思路可以看出,Raft中最为核心的部分是leader election和log replication。
leader election用来选出新的leader,Raft将运行过程划分为不同的term(类似于VR中的view),每个term都由leader election开始,且每个term中最多只存在一个leader,Raft中所有的通信消息都包含有副本本地的current term,相当于整个系统的逻辑时钟。
Raft中所有的follower需要定期接收到来自leader的心跳消息,并各自维护一个超时计时器,如果在计时器完结时没有收到心跳消息,该follower认为leader发生了故障,开始执行leader election,具体流程如下:
- 该副本增加自己的current term并转换为candidate状态,它将为自己投票并向其他副本发出请求投票的消息。
- 如果candidate收到来自于更新term(current term大于或等于自己的值)的leader发来的消息,则认同该leader,转换为follower继续运行。
- 当副本接收到来自其他副本请求投票的消息时,如果该投票请求的current term大于自己的term,则首先更新自己的current term,然后它将对比本地log与发出请求投票消息的candidate的log哪个比较新(比较log最后条目的index和term,见下文),如果本地的比较新,则拒绝为该candidate投票,反之对candidate投票。另外,每个副本在每个term中仅能投出一票。
- 当candidate收集到超过总数一半的投票时,它将变为新的leader并作为leader开始工作。
在leader election的过程中有可能出现一种情况,称为”split vote”:多个follower几乎同时转换为candidate并发起投票,结果最后没有任何一个candidate获得了足够的投票,当出现这种情况时,candidate会在等待超时后进入下一个term重新开始leader election,为了避免这种的情形重复发生,Raft中每个副本随机选择超时时间(论文中例子为在150-300ms中),降低了冲突发生的可能性。
当完成leader election后,Raft进入新的term开始工作, leader接受到client的请求后,会为该操作生成一条log项,并同时记录该项的index(表明该项在log中的位置)和term,如下图:
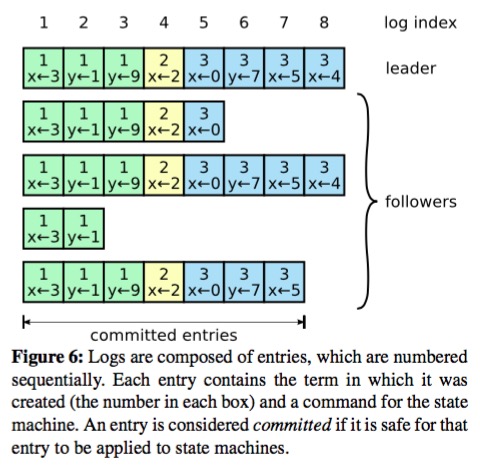
Raft中的log
然后,leader会向所有follower发送该请求,将该log项传播出去,如果有副本失败的情况,leader会不断执行重传。当leader成功将该log项复制到超过一半的副本上后,leader认为该log项(及其之前的所有log项)可以被提交了(仅限于当前term的log项,见下文),它将在本地状态机执行对应操作,并向client返回执行结果,leader记录已提交的最高index,并告知follower,follower据此知晓已确认提交的操作并在本地执行。
在正常运行中以上的过程就足够了,然而在考虑到各类故障的影响,各个副本上的log可能会出现各种不一致的情况,如下图:
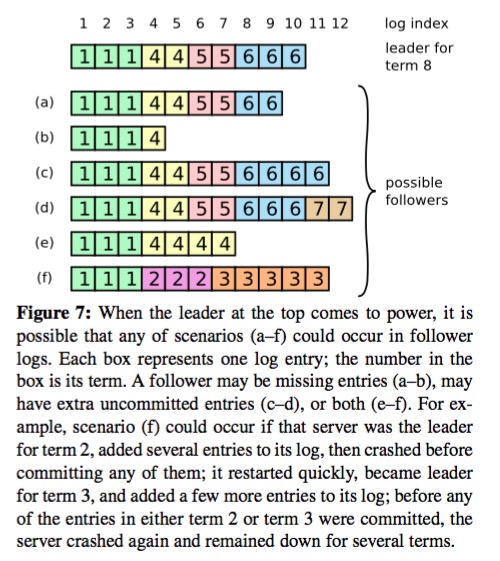
log不一致
Raft用来处理这种情况的对策很简单:以leader上的日志为准,将与leader不一致的日志进行重写(这个过程比较繁琐,但思路是简单的,通过不断向前检查follower上log项,直到找到分叉点,然后进行修正)。这样的重写使得旧term中遗留的log项可能出现被覆盖丢失的情况,如下图:

Raft中旧term日志覆盖问题
因此,Raft约束对于来自旧term的log项不能根据多数原则提交,而只能随着当前term的log项一起提交。
正确性
Raft的完整的正确性证明在论文中推倒的非常详细,我实在做不出什么精简,其核心证明过程在于在整个算法中保证下图中的几点性质:

Raft中的Safety保证
可以看到通过这几点性质,Raft满足了Safety要求,但其在Liveness上是有缺陷的,例如leader election过程可能会出现无法完成的情况,虽然出现概率非常非常低,在实践中可以忽略不计,但从理论证明角度是无法确保Liveness的。
其中有一点非常值得注意,在VR中任何副本都可以作为新的primary,而Raft则不同,Raft的leader election过程保证了只有包含原term中所有已提交log项的candidate才能够被选为leader(因为要获取一半以上投票),这样通过对leader的选择过程做出了限制,Raft做到了log的单向传递:仅从leader传递到follower,而没有相反方向。
另外,Raft和VR一样,通过屏蔽旧term的消息,将异步系统改造成为了半同步系统,绕过了FLP不可能性结论。
Paxos
Paxos是一个传奇。
Paxos是Lamport宗师在1998年首次公开的9,最初的描述使用希腊的一个城邦Paxos作为比喻,描述了Paxos中通过决议的流程,并以此命名这个算法。后来在2001年,Lamport觉得同行不能理解他的幽默感,于是重新发表了朴实的算法描述版本《Paxos Made Simple》。
自Paxos问世以来就持续垄断了分布式共识算法,Paxos这个名词几乎等同于分布式共识(直到Raft问世?),Google更是对Paxos算法宠爱有加,在Chubby、Megastore10以及Spanner11中都声称自己使用Paxos来解决分布式共识问题。
然而,Paxos的最大特点就是“难”…不仅难以理解,而且难以实现。
系统模型
Paxos同样运行在允许故障-停止的异步系统中,并且不要求可靠的消息传递,及可以容忍消息丢失、延迟、乱序以及重复。
容错
在一个总共有\(2f+1\)个进程的Paxos部署中,可以容忍最多不超过\(f\)个进程同时发生故障。
Paxos与多副本状态机
Paxos和之前介绍的两个算法不同,Paxos是一个独立的分布式共识算法,为了与前文一致,先介绍一下如何在Paxos算法的基础下实现多副本状态机。
我们先将Paxos作为黑盒对待,一个Paxos实例(指运行一次Paxos算法)可以使多个进程在一个值上达成一致,为了实现多副本状态机,核心在于使所有的副本按照一致的顺序执行操作序列,那么我们可以同时运行多个独立的Paxos实例(带序号),第\(i\)个Paxos实例决定的值就是状态机日志中第\(i\)项操作。
原理介绍
打开黑盒。
Paxos算法的设计过程就是从正确性开始的,对于分布式共识问题,很多进程提出(propose)不同的值,共识算法保证最终只有其中一个值被选定,Safety表述如下:
- 只有被提出(propose)的值才可能被最终选定(chosen)。
- 只有一个值会被选定(chosen)。
- 进程只会获知到已经确认被选定(chosen)的值。
Paxos以这几条约束作为出发点进行设计,只要算法最终满足这几点,正确性就不需要证明了。Paxos算法中共分为三种参与者:proposers、acceptors以及learners,通常实现中每个进程都同时扮演这三个角色。
proposers向acceptors提出proposal,为了保证最多只有一个值被选定(chosen),proposal必须被超过一半的acceptors所接受(accept),且每个acceptor只能接受一个值(Paxos算法的出发点,易于理解但难以实现,后面会被修改)。
为了保证正常运行(必须有值被接受),所以Paxos算法中:
先来先服务,合情合理。但这样产生一个问题,如果多个proposers同时提出proposal,很可能会导致无法达成一致,因为没有propopal被超过一半acceptors的接受,因此,acceptor必须能够接受多个proposal,不同的proposal由不同的编号(可以有各种实现方式)进行区分,当某个proposal被超过一半的acceptors接受后,这个proposal就被选定了。
既然允许acceptors接受多个proposal就有可能出现多个不同值都被最终选定的情况,这违背了Safety要求,为了保证Safety要求,Paxos进一步提出:
只要算法同时满足P1和P2,就保证了Safety。P2是一个比较宽泛的约定,完全没有算法细节,我们对其进一步延伸:
如果满足P2a则一定满足P2,显然,因为只有首先被接受才有可能被最终选定。但是P2a依然难以实现,因为acceptor很有可能并不知道之前被选定的proposal(恰好不在接受它的多数派中),因此进一步延伸:
更进一步的:
满足P2c即满足P2b即满足P2a即满足P2。至此Paxos提出了proposer的执行流程,以满足P2c:
- proposer选择一个新的编号\(n\),向超过一半的acceptors发送请求消息,acceptor回复: (a)承诺不会接受编号比\(n\)小的proposal,以及(b)它所接受过的编号比\(n\)小的最大proposal(如果有)。该请求称为prepare请求。
- 如果proposer收到了超过一半acceptors的回复,它就可以提出proposal了,proposal的值为收到回复中编号最大的proposal的值,如果没有这样的值,则可以自由提出任何值。
- 向收到回复的acceptors发送accept请求,请求对方接受提出的proposal。
仔细品味proposer的执行流程,其完全吻合P2c中的要求,但你可能也发现了,当多个proposer同时运行时,有可能出现没有任何proposal可以成功被接受的情况(编号递增的交替完成第一步),这就是Paxos算法的Liveness问题,有些文档中称其为“活锁”,论文中建议通过对proposers引入选主算法选出distinguished proposer来全权负责提出proposal来解决这个问题,但是即使在出现多个proposers同时提出proposal的情况时,Paxos算法也可以保证Safety。
接下来看看acceptors的执行过程,和我们对P2做的事情一样,我们对P1进行延伸:
易见,P1a包含了P1,对于acceptors:
- 当收到prepare请求时,如果其编号\(n\)大于之前所收到的prepare消息,则回复。
- 当收到accept请求时,仅当它没有回复过一个具有更大编号的prepare消息,接受该proposal并回复。
以上涵盖了满足P1a和P2b的一套完整共识算法,其中一点优化在于acceptor可以提前终止较小编号的proposal过程。
Paxos算法中的另一部分是learners如何知晓已被选中的proposal,本文不再展开。
多说两句
观察Paxos和前文中的VR和Raft算法,最大的区别在于Paxos是“非集中式”的,在Paxos中不存在地位特殊的进程,引入选主也只是因为多个活动的proposers可能导致活锁;VR和Raft是基于“集中式”的设计的,它们在算法中自带了选主,并要求在每个“view”或“term”中只能存在一个leader,由leader来负责定序等操作,这样极大的简化了设计和实现的难度,在系统设计中,简单不一定是个坏事,即使是使用了Paxos算法的Chubby系统,实际上也只是使用Paxos来完成选主,当选主结束后Chubby仍然是作为一个“集中式”的系统来运行的。
另外,Paxos算法作为一个理论工作,它的实现难度不容忽视,分布式系统的设计者往往从Paxos开始,但由于实现难度大而不得不做一些这样那样的修改,这样的修改看似无妨,却极有可能导致最终实现一个没有理论证明的算法(比如Zab)。即使是Google的Chubby工程师团队,在实现Paxos的过程中也吃尽了苦头,他们在发表的关于Paxos工程实现的文章12中如此评论:
There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system. In order to build a real-world system, an expert needs to use numerous ideas scattered in the literature and make several relatively small protocol extensions. The cumulative effort will be substantial and the final system will be based on an unproven protocol.
那么,是否Raft可以取Paxos而代之呢?我还不知道…留待以后在实践中思考。
延伸思考
多副本状态机在本质上是一种副本技术,我们使用副本技术的目的往往是容错和负载均衡,不但要保证副本能够容忍进程故障,也希望能通过负载均衡提高整体的性能。
我们可以看到前文中描述的几个多副本状态机性能都十分有限,首先,它们都只有leader节点可以处理请求,而从节点只是作为副本保障容错性;第二点,在这样的多副本状态机中,读请求也是作为一个常规操作执行的,也就是说单纯的读操作也需要在多副本状态机中产生消息交互并生成对应的日志条目,限制了单纯的读请求执行效率。
在我所了解的一些系统中,已经有了不少优秀的思路可以用来提高多副本状态机的性能。
针对读请求多的场景,Harp13提出了一种方法:针对读请求这类不影响状态机状态的操作,可以不将其作为需要在状态机副本中同步的操作,而直接由leader副本处理,这样产生的一个问题是可能会由于网络分区等异常而读到失效的错误信息,违背了副本的线性化能力(强一致性),可以通过对leader引入Leases14机制来消除这个问题,只要当leader持有Lease,就可以直接响应读请求,而其他副本也保证在Lease失效前不会产生新的leader,因此保证了一致性要求。更进一步的,如果系统可以接受更加放松的一致性要求,则可以允许非leader节点响应读请求,达到负载均衡的效果,通过对client的请求引入向量时钟(vector timestamps)或Lamport时钟,可以在这样的模式中实现较弱的一致性要求。
另一种解决思路是为多副本状态机加入缓存机制,例如Chubby和Zookeeper都在client端为数据做了缓存,在Chubby中client只允许访问leader进程,但对数据使用了基于Leases的缓存机制,保证了副本的线性化能力;而Zookeeper则放松了一致性要求,client不仅可以访问非leader的副本,而且使用“watch”机制提高系统处理能力。Chubby的设计者认为使用较弱的一致性模型会造成用户的困惑,而具备线性化能力的副本行为要更加容易被程序员所接受,但Zookeeper的设计者认为程序员应该理解所使用服务的一致性保证,并将进行更强一致性操作选择权交给了程序员用户(Zookeeper提供sync API),这就是性能和一致性之间常有的trade off,留给每个系统设计者思考。
参考资料
- Coulouris G F, Dollimore J, Kindberg T. Distributed systems: concepts and design[M]. pearson education, 2005. ↩
- Hunt P, Konar M, Junqueira F P, et al. ZooKeeper: Wait-free Coordination for Internet-scale Systems[C]//USENIX Annual Technical Conference. 2010, 8: 9. ↩
- Reed B, Junqueira F P. A simple totally ordered broadcast protocol[C]//proceedings of the 2nd Workshop on Large-Scale Distributed Systems and Middleware. ACM, 2008: 2. ↩
- Fischer M J, Lynch N A, Paterson M S. Impossibility of distributed consensus with one faulty process[J]. Journal of the ACM (JACM), 1985, 32(2): 374-382. ↩
- Burrows M. The Chubby lock service for loosely-coupled distributed systems[C]//Proceedings of the 7th symposium on Operating systems design and implementation. USENIX Association, 2006: 335-350. ↩
- Liskov B, Cowling J. Viewstamped replication revisited[J]. 2012. ↩
- Ongaro D, Ousterhout J. In search of an understandable consensus algorithm[C]//2014 USENIX Annual Technical Conference (USENIX ATC 14). 2014: 305-319. ↩
- Lamport L. Paxos made simple[J]. ACM Sigact News, 2001, 32(4): 18-25. ↩
- Lamport L. The part-time parliament[J]. ACM Transactions on Computer Systems (TOCS), 1998, 16(2): 133-169. ↩
- Baker J, Bond C, Corbett J C, et al. Megastore: Providing Scalable, Highly Available Storage for Interactive Services[C]//CIDR. 2011, 11: 223-234. ↩
- Corbett J C, Dean J, Epstein M, et al. Spanner: Google’s globally distributed database[J]. ACM Transactions on Computer Systems (TOCS), 2013, 31(3): 8. ↩
- Chandra T D, Griesemer R, Redstone J. Paxos made live: an engineering perspective[C]//Proceedings of the twenty-sixth annual ACM symposium on Principles of distributed computing. ACM, 2007: 398-407. ↩
- Liskov B, Ghemawat S, Gruber R, et al. Replication in the Harp file system[M]. ACM, 1991. ↩
- Gray C, Cheriton D. Leases: An efficient fault-tolerant mechanism for distributed file cache consistency[M]. ACM, 1989. ↩