
“一团糟” – 我对OpenStack网络实现的第一感觉
OpenStack的网络模块相信不会有人否认是整个OpenStack中最复杂的部分,即使是OpenStack社区的成员也常常被网络模块的复杂性搞的焦头烂额。因为研究负载均衡的关系,我不得不对网络模块进行一点粗浅的了解,这里按照个人的理解把这些东西总结起来写下来。
本文算不上是的OpenStack网络分析(没有实力写),但求可以以自己的一些粗浅理解,为想要一窥OpenStack网络实现的同学提供哪怕一点点帮助。
PS:本文中所描述的所有概念和实现均基于OpenStack当前版本(neutron git version : 2921d3c686b5f5cd68d51f906766983f975b1cf2),在此也强烈建议任何想要了解OpenStack网络的同学一定要实际搭建一个可用的环境来对其中网络的每一个环节进行推敲。
1. 一点点历史
如大家所知,OpenStack主要提供的服务分为计算、存储和网络三部分,在OpenStack早期,网络服务由nova-network模块负责提供(支持Flat、FlatDHCP和VLAN三种模式,在现在的文档中通常被称为Legacy networking,从名字就可以看到被淘汰的命运)。随着OpenStack的发展,朴素的nova-network模块逐渐无法满足云环境中复杂的网络需求,最主要原因的在于:公有云的租户希望有更丰富的网络API和可定制的网络拓扑结构。因此,OpenStack决定另起炉灶,为网络服务单独打造一个子项目:Quantum。
诶?为啥是这货?文档上不都叫Neutron么?没错,Quantum是OpenStack network最早的名字,后来因为这个名字被使用的太多了,在Google上不方便搜索,于是改名为Neutron(囧rz,待考证),所以在学习过程中如果看到Quantum不要慌张,就是这货没错。
2. 积木
OpenStack就是开源软件的堆叠,它的网络模块也不例外:Neutron模块基于当前已有的开源技术来解决虚拟网络问题,想了解Neutron就必须要对这些“积木”先有最基本的认识,否则可真的是雾里看花。
下面简单罗列出其中最为重要的组件,如果感觉不太熟悉的话:Google一下,海量文档等你翻阅…
- OpenvSwitch:开源的虚拟交换机实现,虚拟网络利器,支持OpenFlow、VLAN、GRE、VXLAN…
- Linux bridge:Linux虚拟网桥组件,Neutron中主要用来实现安全组和访问规则(见下文)
- GRE、VXLAN:三层隧道技术
- Linux Namespace:Linux内核支持的、对资源进行隔离的机制(Neutron中主要用到了网络部分),不清楚的同学建议看看陈皓的这篇“马桶风格”的科普文
- iptables:不说了,大家都很熟悉了
- HAproxy:大名鼎鼎的开源负载均衡项目,Neutron-LBaaS默认使用它作为负载均衡器
3. OpenStack网络核心概念
Neutron中对网络抽象的最核心的概念是Network、Port和Subnet,关系如下图:
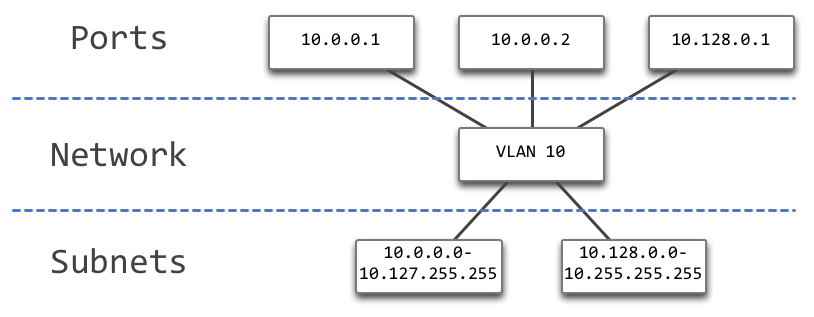
Neutron抽象网络概念
Network是OpenStack中一个独立的连通二层网络,Port是连接在网络上的接口,Subnet是对应Network上的一块IP地址。注意这里不要过多的纠结OSI模型中的层次关系,这些术语是Neutron自身对网络的抽象概念,和OSI模型中的术语并不是一一对应的。
另一组非常重要也非常容易被混淆的概念是Provider Network和Tenant Network,解释如下:
- Provider Network:只能由管理员创建,是已经存在的物理网络在Neutron中的映射。典型的例子是将公网作为Provider Network(通常是 br-ex 的映射(见后文))来创建External Network
- Tenant Network:字面意思,租户创建的虚拟网络
这些概念术语在下文中多次出现,非常重要。
4. Neutron模块组成
Neutron本身只负责实现网络抽象API,充分采用了插件化的设计,只要可以实现Neutron网络API就可以,可以说非常灵活。
总的来说,插件分为两类:Core Plugin和Service Plugin。
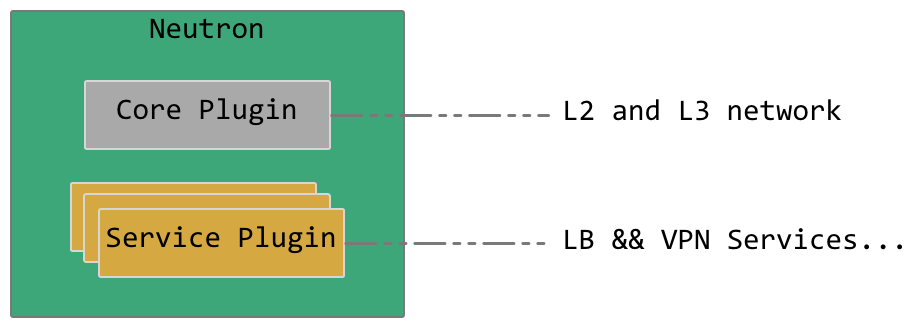
Neutron插件结构
Core Plugin实现对二层和三层网络的抽象(链路层和IP层),如名字所暗示的,Core Plugin必须启用才能保证Neutron的正常运行。二层插件Modular Layer 2 Plugin(ML2)又通过使用具体的Type driver(Local, Flat, VLAN, GRE, VXLAN – 负责对应类型网络的虚拟化)和Mechanism driver(OpenvSwitch, Linux bridge – 实际的网络实现机制)来实现二层网络的模拟工作;三层插件主要通过驱动L3-Agent和DHCP-Agent来提供虚拟的三层网络服务。
Service Plugin则是基于Core Plugin提供的功能来提供额外的服务,如LBaaS插件提供负载均衡服务、VPNaaS提供VPN服务等。
5. Neutron网络逻辑结构
有了上面这些复杂的概念,接下来我们可以看看Neutron到底是如何实现它的看家本领的:租户网络隔离和自定义网络拓扑。
租户网络隔离实现起来说白了还是得靠VLAN,不过和nova-network中的VLAN模式(通过不同的Linux bridge连接到支持VLAN的物理交换机上)不同,Neutron在OpenvSwitch提供的虚拟交换机中使用VLAN。乍一看好像差不多么,不就是换成了虚拟交换机而已?这样做的好处在于:一来可以回避VLAN网络数量上限4096的问题(GRE和VXLAN类型,见下文),二来为自定义网络拓扑创造了机会。
下图展示是Neutron网络实现的最核心的思路,注意图中将整个OpenStack视为整体,忽略了物理机之间的边界:
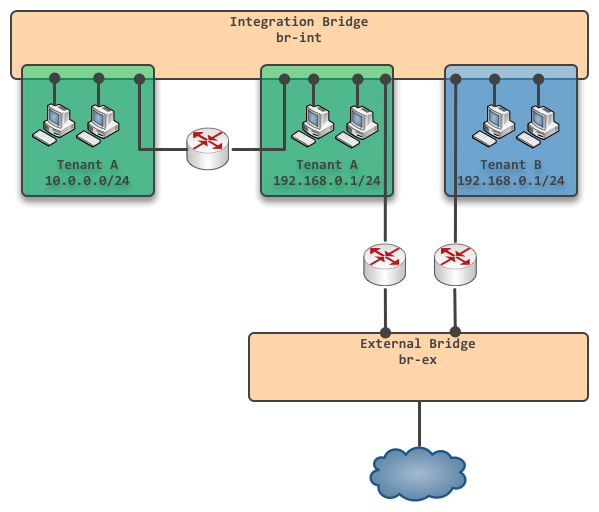
不考虑物理机边界时的Neutron网络实现
整个Neutron网络实现的核心就是图中的两个OpenvSwitch虚拟网桥 br-int 和 br-ex。
br-int 是集成网桥,在逻辑概念上,它是跨越整个OpenStack的内部大网桥:所有的Port(虚拟机、虚拟路由器、DHCP等等)都直接连接在 br-int 上,通过不同的VLAN tag来区分不同的Subnet,做到了独立网络之间的隔离(在这里我们暂且认为 br-int可以创建任意多的VLAN,后文中会继续分析实际场景中的VLAN数量问题)。
通过在两个Subnet间创建虚拟路由器,可以实现两个不同Subnet之间的互通,如上图中左上方的虚拟路由器实现了租户A两个网络间的互通。 br-ex是外部网络所连接的网桥(该网口不设IP地址),通过在Tenant Network中创建连通 br-ex的虚拟路由器,即可以实现对外网的访问(对External Network的访问默认采用SNAT的方式)。
6. 跨越物理机界限
然而,理想很丰满,现实却很骨感。虽然上面的逻辑结构非常简单统一,似乎直接解决了虚拟网络的问题,但却终归只是概念上的设计,在现实世界中必须要面对一个最大的问题:集成网桥 br-int是没有办法理想化的跨越所有物理机的,那么我们该如何解决这个问题?该怎样做才能将实际上分散在各个物理机上的 br-int网桥连通,实现逻辑上统一的集成网桥呢?
Neutron可以采用三种方法来完成这一任务:VLAN、GRE和VXLAN,分别对应三种Tenant Network类型,每一个用户创建的Tenant Network根据其类型决定内部网络采用什么样的方式来跨越物理机的界限。
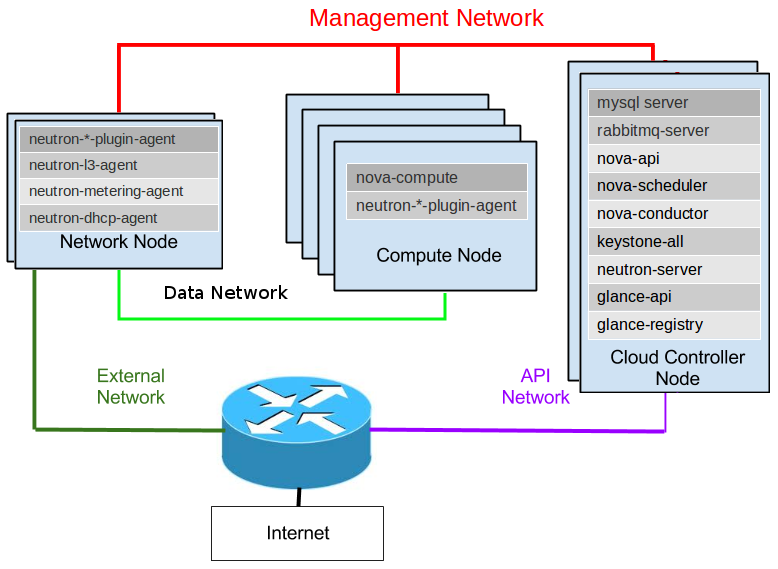
OpenStack集群标准网络部署图
上图是OpenStack安装文档中对整体OpenStack节点配置和网络部署的解释,Neutron关心的是其中的Network Node和Compute Node,Compute Node是集群中承载虚拟机运行的节点,Network Node主要负责提供网络API和三层网络服务。 br-int网桥分散在这些节点中,下面我们分别看看如何通过VLAN、GRE和VXLAN的方式解决这一问题。
6.1. VLAN
通过VLAN来连接分散在不同物理机中不同的租户网络实际上和nova-network的VLANManager在想法上是一脉相承的,都是为每一个租户网络分配一个物理交换机上的VLAN,在连接所有节点的同时通过不同的VLAN保证了租户网络的隔离性。
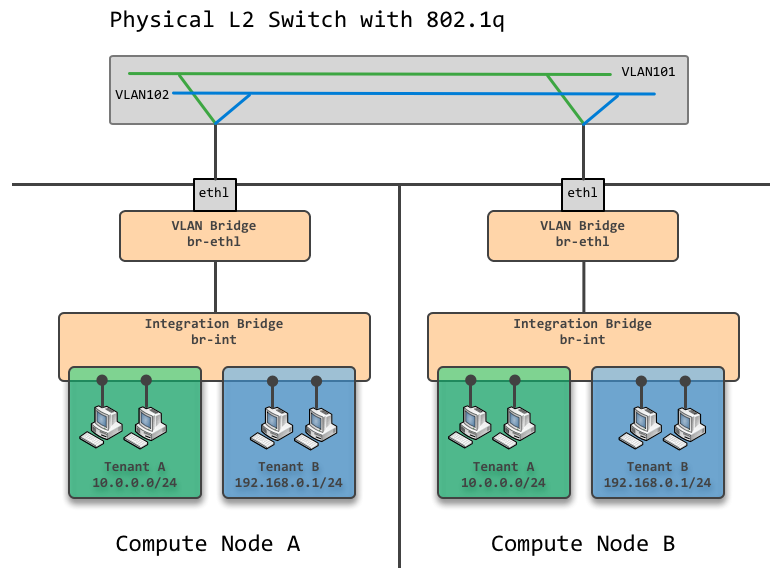
VLAN模式网络
如图所示是两个不同的Compute节点的网络部署,两个节点之间通过一个支持VLAN的物理交换机连接起来。并且分别创建了OpenvSwitch网桥 br-eth1与 br-int相连。
理解VLAN模式的关键在于将两个不同的VLAN区分清楚:一个是 br-int上分隔Tenant Network的虚拟交换机VLAN,另一个是Data Network中的物理交换机VLAN。Neutron VLAN模式的本质就是将Data Network中的VLAN作为Provider Network,并将租户网络映射到真实的物理交换机VLAN中。
如图例中,绿色的Tenant A网络映射到了物理VLAN 101中,而蓝色Tenant B网络映射到了物理VLAN 102中,这样就在保持隔离的同时实现了不同Compute Node之间的网络互通。另外注意重要的一点:为了将虚拟交换机中的VLAN映射到物理交换机的VLAN中,需要对VLAN tag进行修改,这一步骤是在 br-eth1上借由Open Flow实现的,官方文档对此有详细的讲解,参见这里。
6.2. GRE & VXLAN
GRE和VXLAN的方式原理上非常相似,都是通过三层隧道的方法将虚拟交换机的报文用三层协议封装,发送给隧道对应端后再由对端将三层报文脱掉得到原报文后转交给虚拟网络,下面以GRE为例进行说明。
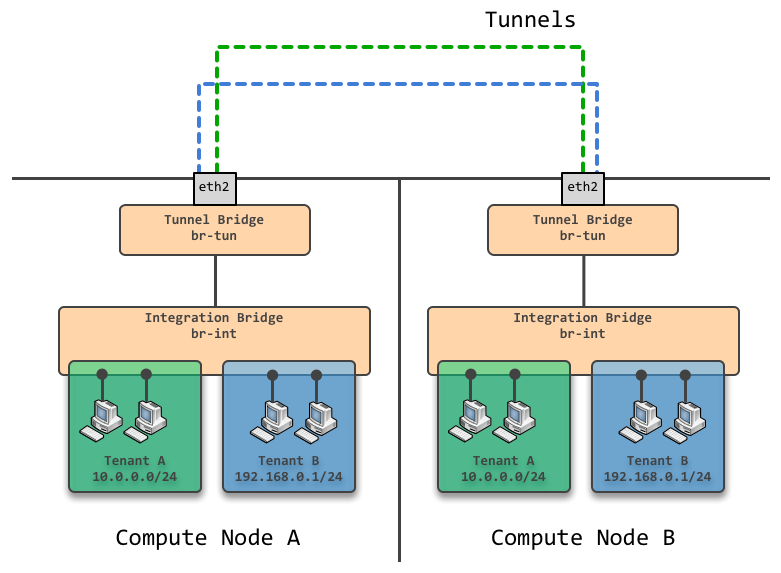
GRE模式网络
上图中可以看到两个Compute Node中分别创建了隧道网桥 br-tun与 br-int相连,并且为每个租户网络在节点间创建了对应的点对点GRE隧道,在计算节点上使用命令 sudo ovs-vsctl show 查看这些隧道:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[kongfy@3E ~]$ sudo ovs-vsctl show ... Bridge br-tun fail_mode: secure Port "gre-c0a801df" Interface "gre-c0a801df" type: gre options: {df_default="true", in_key=flow, local_ip="192.168.1.122", out_key=flow, remote_ip="192.168.1.223"} Port "gre-c0a80166" Interface "gre-c0a80166" type: gre options: {df_default="true", in_key=flow, local_ip="192.168.1.122", out_key=flow, remote_ip="192.168.1.102"} Port patch-int Interface patch-int type: patch options: {peer=patch-tun} Port br-tun Interface br-tun type: internal |
隧道网桥 br-tun所做的重要的工作就是将所有的租户网络分别映射到对应的GRE隧道ID上,通过Open Flow来在 br-int网络流的VLAN tag和GRE隧道ID之间做转换。另外,GRE隧道的ID字段长度为32位,也就是说只要各个节点做好 br-int上的VLAN tag和GRE ID之间的转换,我们可以创造2^32个租户网络(VXLAN中VNI字段也有24位长,即可以创建2^24个租户网络)!这里隐藏一个潜在的限制,每个单独的节点上不能有超过4096个租户网络…目前来说这对Compute Node来说并不是问题(单节点虚拟化4096个虚拟机是难以想象的),而对网络节点来说,可以使用多台网络节点来解决这个问题。
6.3. 选择?
那么我们该如何在这几种方法中选择呢?
首先网络效率最高的无疑是VLAN的方式,因为没有涉及到三层隧道报头的开销,而缺点在于无法突破VLAN tag 4096的上限,因此VLAN方式无疑是非常适合于追求性能而Tenant Network数量有限的私有云环境。在公有云环境中由于Tenant Network的数量要大得多,所以往往选择隧道方式实现,在OpenStack节点数量比较多时,由于GRE隧道是点对点的隧道,所以会导致创建的隧道数量过多引起广播风暴(详细说明),因此似乎基于UDP的VXLAN是公有云部署在大型数据中心的更好选择?(待考证)
7. 虚拟路由的实现
到现在我们已经看到了Neutron是如何实现租户网络隔离的。但是对用户自定义网络拓扑功能的讨论还欠缺最为重要的一环:虚拟路由器(Router)。
在Juno版本之前,三层网络的所有服务:包括虚拟路由器、DHCP等等都部署在Network Node上(Juno版本推出了Distributed Virtual Router功能,用来解决Network Node的单点故障问题并减轻数据中心网络中不必要的数据传输,这些内容超出了本文的讨论范围,感兴趣的同学可以看看这个)。虚拟路由器的实现实际上可以说是非常“朴素”的,Neutron在网络节点上创建对应虚拟路由器接口的Internal Port,将这些设备接入 br-int设置VLAN tag(Tenant Network)或者直接接入 br-ex(External Network),实际负责包转发的就是Network Node的内核本身,为了防止网络地址重叠,要把虚拟路由器相关的这些Internal Port放进独立的网络Namespace中。
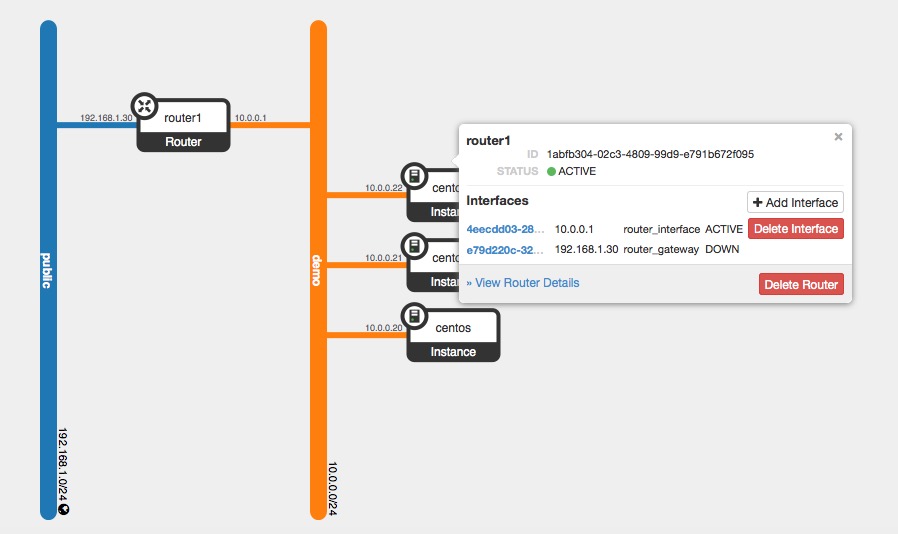
demo虚拟网络拓扑
上图是在我的实验环境中创建的虚拟网络(10.0.0.0/24),通过一个虚拟路由器连接到外网(没错,就是192.168.1.0/24网段)。在Network Node上通过命令 ip netns 来查看当前有哪些Namespace:
|
1 2 3 |
[kongfy@3E ~]$ ip netns qrouter-1abfb304-02c3-4809-99d9-e791b672f095 qdhcp-ffdfe83f-6b00-4a53-8a2e-822cdc73f518 |
qrouter-XXX就是虚拟路由器使用的Namespace,使用 sudo ip netns exec qrouter-1abfb304-02c3-4809-99d9-e791b672f095 ifconfig 命令查看该空间内的网络接口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
[kongfy@3E ~]$ sudo ip netns exec qrouter-1abfb304-02c3-4809-99d9-e791b672f095 ifconfig lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 0 (Local Loopback) RX packets 34 bytes 3672 (3.5 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 34 bytes 3672 (3.5 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 qg-e79d220c-32: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.1.30 netmask 255.255.255.0 broadcast 192.168.1.255 inet6 fe80::f816:3eff:fe8b:733c prefixlen 64 scopeid 0x20<link> ether fa:16:3e:8b:73:3c txqueuelen 0 (Ethernet) RX packets 212399 bytes 250859260 (239.2 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 104055 bytes 10311601 (9.8 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 qr-4eecdd03-28: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.0.0.1 netmask 255.255.255.0 broadcast 10.0.0.255 inet6 fe80::f816:3eff:fee5:9019 prefixlen 64 scopeid 0x20<link> ether fa:16:3e:e5:90:19 txqueuelen 0 (Ethernet) RX packets 105590 bytes 10530770 (10.0 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 201200 bytes 249954273 (238.3 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 |
果不其然,接口的IP和虚拟路由器接口配置完全一样。再来查看空间内的路由策略:
|
1 2 3 4 5 6 |
[kongfy@3E ~]$ sudo ip netns exec qrouter-1abfb304-02c3-4809-99d9-e791b672f095 route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 qg-e79d220c-32 10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 qr-4eecdd03-28 192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 qg-e79d220c-32 |
非常朴素的路由表,最后一步,检查一下 qr-4eecdd03-28 和 qg-e79d220c-32 这两个接口接在哪里了?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
[kongfy@3E ~]$ sudo ovs-vsctl show 2589affe-8d13-4c1e-be9d-1a3f3603454b Bridge br-ex Port phy-br-ex Interface phy-br-ex type: patch options: {peer=int-br-ex} Port "enp4s2" Interface "enp4s2" Port "qg-e79d220c-32" Interface "qg-e79d220c-32" type: internal Port br-ex Interface br-ex type: internal Bridge br-int fail_mode: secure Port "qvof6da39de-53" tag: 1 Interface "qvof6da39de-53" Port patch-tun Interface patch-tun type: patch options: {peer=patch-int} Port "qr-4eecdd03-28" tag: 1 Interface "qr-4eecdd03-28" type: internal Port br-int Interface br-int type: internal Port "tap2c04d868-02" tag: 1 Interface "tap2c04d868-02" type: internal Port int-br-ex Interface int-br-ex type: patch options: {peer=phy-br-ex} Port "tapdf3bd4f1-19" tag: 1 Interface "tapdf3bd4f1-19" type: internal |
一端接在External Network网桥 br-ex 上,另一端接在 br-int 上并且VLAN tag为 1(Tenant Network),是不是有豁然开朗的感觉~
8. Floating IP
为了让我们的虚拟机可以对外网提供服务,首先我们需要一个可访问的外网地址。这个功能在OpenStack体系中是通过Floating IP来实现的。
Floating IP即外网可访问的IP地址,可以绑定到Tenant Network的任意Port。Floating IP的概念是从nova-network继承下来的,虽然实现方式已经完全不一样了。
有了前面对虚拟路由器的讨论,Floating IP的实现实际上是水到渠成的事情。既然Tenant Network和External Network的互通需要连接虚拟路由器,那么Floating IP的实现只需要在这个虚拟路由器上添加相应的DNAT规则即可。
同样以上节例子中的虚拟网络为例,我将Floating IP 192.168.1.31绑定到虚拟机10.0.0.22上,通过iptables查看NAT表:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
[kongfy@3E ~]$ sudo ip netns exec qrouter-1abfb304-02c3-4809-99d9-e791b672f095 iptables -t nat -S -P PREROUTING ACCEPT -P INPUT ACCEPT -P OUTPUT ACCEPT -P POSTROUTING ACCEPT -N neutron-l3-agent-OUTPUT -N neutron-l3-agent-POSTROUTING -N neutron-l3-agent-PREROUTING -N neutron-l3-agent-float-snat -N neutron-l3-agent-snat -N neutron-postrouting-bottom -A PREROUTING -j neutron-l3-agent-PREROUTING -A OUTPUT -j neutron-l3-agent-OUTPUT -A POSTROUTING -j neutron-l3-agent-POSTROUTING -A POSTROUTING -j neutron-postrouting-bottom -A neutron-l3-agent-OUTPUT -d 192.168.1.31/32 -j DNAT --to-destination 10.0.0.22 -A neutron-l3-agent-POSTROUTING ! -i qg-e79d220c-32 ! -o qg-e79d220c-32 -m conntrack ! --ctstate DNAT -j ACCEPT -A neutron-l3-agent-PREROUTING -d 169.254.169.254/32 -i qr-+ -p tcp -m tcp --dport 80 -j REDIRECT --to-ports 9697 -A neutron-l3-agent-PREROUTING -d 192.168.1.31/32 -j DNAT --to-destination 10.0.0.22 -A neutron-l3-agent-float-snat -s 10.0.0.22/32 -j SNAT --to-source 192.168.1.31 -A neutron-l3-agent-snat -j neutron-l3-agent-float-snat -A neutron-l3-agent-snat -o qg-e79d220c-32 -j SNAT --to-source 192.168.1.30 -A neutron-l3-agent-snat -m mark ! --mark 0x2 -m conntrack --ctstate DNAT -j SNAT --to-source 192.168.1.30 -A neutron-postrouting-bottom -m comment --comment "Perform source NAT on outgoing traffic." -j neutron-l3-agent-snat |
9. 数据流
有了上面这些网络知识,终于可以从全局的角度看看在虚拟网络中数据包的走向了:
- 同一Tenant Network,同一Compute Node:数据包经由本机 br-int直接到达目的端口
- 同一Tenant Network,不同Compute Node:数据包穿过本机 br-int,通过 br-tun 上的VLAN/GRE/VXLAN方式到达目标Compute Node,相反方向穿过 br-tun和 br-int,到达目标端口
- 不同Tenant Network:数据包穿过本机 br-int,通过 br-tun上的VLAN/GRE/VXLAN方式到达Network Node,相反方向穿过 br-tun和 br-int到达路由器端口,由路由器转发报文,路径和之前描述的是一样的
- 访问External Network:数据包穿过本机 br-int,通过 br-tun上的VLAN/GRE/VXLAN方式到达Network Node,相反方向穿过 br-tun和 br-int到达路由器端口,由路由器执行NAT后通过 br-ex发送到External Network
好吧,我承认我偷懒了…画图画累了,请各位自行脑补…
10. 安全组 & 访问规则
在结束对Neutron虚拟网络的实现之前,还有一个必须要提到的部分:虚拟机的安全组和访问规则。这是整个Neutron虚拟网络实现中比较tricky的部分,为什么这么说呢?请看下图:
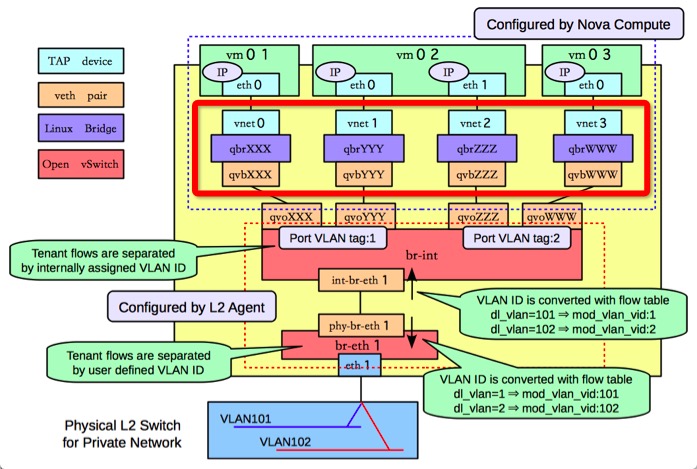
“多余”的网桥?
图是从OpenStack的文档中借来的,主要看我用红色边框框起来的部分,为什么虚拟机不能直接接在 br-int上呢?而是似乎很没用的连接了一个Linux Bridge?答案是为了实现虚拟机的安全组和访问规则功能,这个功能不能直接用OpenvSwitch实现(原因没有仔细研究),所以Neutron做出了妥协。
在Compute Node上使用iptables可以对应虚拟机的详细规则, tapf6da39de-53是我想要查询的虚拟机的TAP设备:
|
1 2 3 4 5 6 |
[kongfy@3E ~]$ sudo iptables -S | grep tapf6da39de-53 -A neutron-openvswi-FORWARD -m physdev --physdev-out tapf6da39de-53 --physdev-is-bridged -m comment --comment "Direct traffic from the VM interface to the security group chain." -j neutron-openvswi-sg-chain -A neutron-openvswi-FORWARD -m physdev --physdev-in tapf6da39de-53 --physdev-is-bridged -m comment --comment "Direct traffic from the VM interface to the security group chain." -j neutron-openvswi-sg-chain -A neutron-openvswi-INPUT -m physdev --physdev-in tapf6da39de-53 --physdev-is-bridged -m comment --comment "Direct incoming traffic from VM to the security group chain." -j neutron-openvswi-of6da39de-5 -A neutron-openvswi-sg-chain -m physdev --physdev-out tapf6da39de-53 --physdev-is-bridged -m comment --comment "Jump to the VM specific chain." -j neutron-openvswi-if6da39de-5 -A neutron-openvswi-sg-chain -m physdev --physdev-in tapf6da39de-53 --physdev-is-bridged -m comment --comment "Jump to the VM specific chain." -j neutron-openvswi-of6da39de-5 |
Chain neutron-openvswi-if6da39de-5控制进入虚拟的规则:
|
1 2 3 4 5 6 7 8 9 10 |
[kongfy@3E ~]$ sudo iptables -L neutron-openvswi-if6da39de-5 Chain neutron-openvswi-if6da39de-5 (1 references) target prot opt source destination DROP all -- anywhere anywhere state INVALID /* Drop packets that appear related to an existing connection (e.g. TCP ACK/FIN) but do not have an entry in conntrack. */ RETURN all -- anywhere anywhere state RELATED,ESTABLISHED /* Direct packets associated with a known session to the RETURN chain. */ RETURN udp -- 10.0.0.2 anywhere udp spt:bootps dpt:bootpc RETURN tcp -- anywhere anywhere tcp multiport dports tcpmux:65535 RETURN all -- anywhere anywhere match-set NETIPv4d2c15a2d-d070-4630-a src RETURN icmp -- anywhere anywhere neutron-openvswi-sg-fallback all -- anywhere anywhere /* Send unmatched traffic to the fallback chain. */ |
Chain neutron-openvswi-of6da39de-5控制从虚拟机出去的规则:
|
1 2 3 4 5 6 7 8 9 10 |
[kongfy@3E ~]$ sudo iptables -L neutron-openvswi-of6da39de-5 Chain neutron-openvswi-of6da39de-5 (2 references) target prot opt source destination RETURN udp -- anywhere anywhere udp spt:bootpc dpt:bootps /* Allow DHCP client traffic. */ neutron-openvswi-sf6da39de-5 all -- anywhere anywhere DROP udp -- anywhere anywhere udp spt:bootps dpt:bootpc /* Prevent DHCP Spoofing by VM. */ DROP all -- anywhere anywhere state INVALID /* Drop packets that appear related to an existing connection (e.g. TCP ACK/FIN) but do not have an entry in conntrack. */ RETURN all -- anywhere anywhere state RELATED,ESTABLISHED /* Direct packets associated with a known session to the RETURN chain. */ RETURN all -- anywhere anywhere neutron-openvswi-sg-fallback all -- anywhere anywhere /* Send unmatched traffic to the fallback chain. */ |
本文到这里可以说达到了阶段性的胜利:完成了Neutron Core Plugin的讨论,探索了Neutron是如何完成虚拟的2&3层网络的。如果你依然感觉一头雾水…我只能深表抱歉,你可以参照官方文档和我下面给出的参考资料来更加详细的了解这部分内容。 ^o^
11. LBaaS
本文的最后一部分内容,介绍一下OpenStack提供的负载均衡服务:LBaaS,这个项目目前属于Neutron项目中,作为Neutron的一个Service Plugin。
负载均衡的功能想必不需要多解释了,无非就是把流量尽可能均衡的分配到后端的各台服务器上,现在流行的解决方案有很多,如硬件的F5、软件的LVS、HAProxy、Nginx等。这些负载均衡手段虽然工作的层次有所不同,但根本目的都是一样的:让各个后端机器获得尽可能均匀的复杂以提高集群整体的处理能力。
那么在云环境中负载均衡很自然的也是非常重要的技术,租户所创建的虚拟机之间也需要进行负载均衡。为什么不能直接使用更大的虚拟机呢?好问题。一来虚拟机的纵向扩展将使服务出现Down time;二来纵向拓展是有上限的:不可能超过真实服务器的承受能力;三来如果一直开着一台很大的低负载虚拟机,就租户而言从计费角度上不太划算,远不如按需的启动和关闭虚拟机来的划算。
根据负载均衡的特点,社区在OpenStack中把负载均衡抽象成下面的概念:
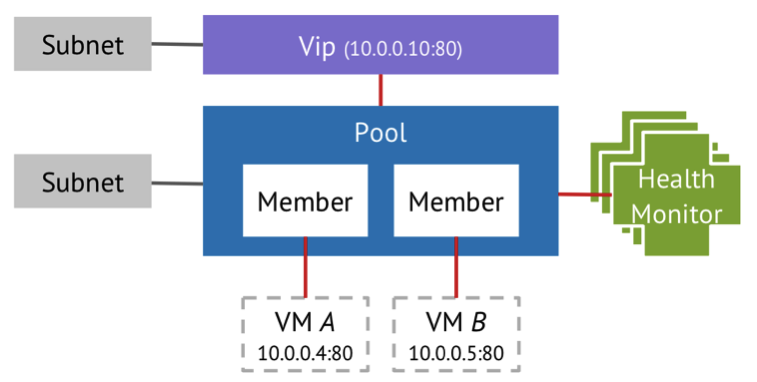
OpenStack的负载均衡模型
其中最为核心的是Pool,代表负载后端的虚拟机池,Pool中包含想要进行负载均衡的虚拟机作为Member,并且要为Pool整体绑定一个VIP作为所有Member的虚拟IP,所有访问虚拟IP的请求将根据设定的负载均衡规则分配到Pool中的Member虚拟机上。最后再为这个VIP对应的Port绑定一个Floating IP,就可以从外网愉快的使用负载均衡下的虚拟机集群了~
实现的网络逻辑如下图所示:
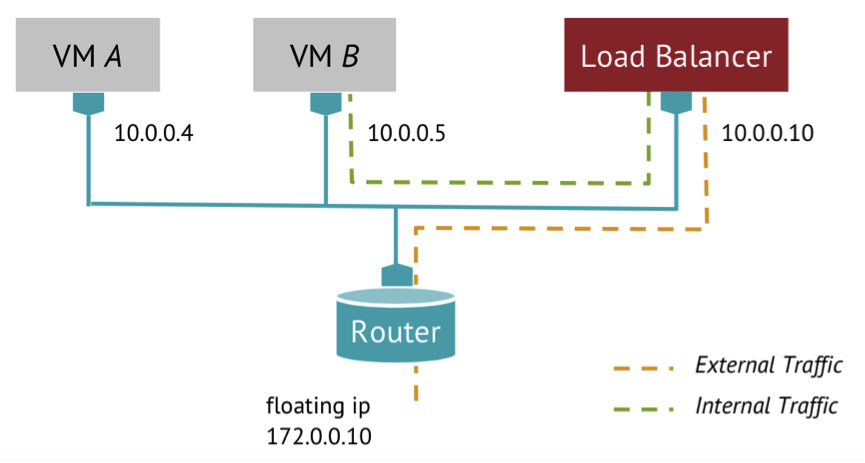
负载均衡网络示意图
LBaaS利用Neutron的网络服务,将Floating IP绑定到Load Balancer的Port上,然后将这些流量通过内部网络均衡的分配给各个虚拟机。很容易看出,最核心的部分就是Load Balancer的实现了,那么Load Balancer是怎么实现的呢?
答案是没有实现…OpenStack直接采用各种开源可用的负载均衡项目来完成负载均衡的任务,默认是HAProxy。LBaaS所做的任务就是根据用户提出的负载均衡要求生成符合要求的HAProxy配置文件并启动HAProxy。
我在我的实验环境中为三台虚拟机(10.0.0.20, 10.0.0.21, 10.0.0.0.22)的80端口(HTTP)配置了负载均衡服务,使用10.0.0.23作为VIP,果然发现了HAProxy进程:
|
1 2 3 4 |
[kongfy@3E ~]$ ps aux | grep haproxy kongfy 3008 0.0 0.0 112612 740 pts/0 S+ 11:42 0:00 grep --color=auto haproxy kongfy 12684 2.1 0.9 199700 35596 pts/14 S+ May05 253:32 python /usr/bin/neutron-lbaas-agent --config-file /etc/neutron/neutron.conf --config-file=/etc/neutron/services/loadbalancer/haproxy/lbaas_agent.ini nobody 23906 0.0 0.0 49692 1300 ? Ss May09 0:20 haproxy -f /opt/stack/data/neutron/lbaas/49717bc1-204c-42a8-9cc2-46db88a70365/conf -p /opt/stack/data/neutron/lbaas/49717bc1-204c-42a8-9cc2-46db88a70365/pid -sf 28415 |
顺藤摸瓜看看HAProxy使用的配置文件:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
global daemon user nobody group nobody log /dev/log local0 log /dev/log local1 notice stats socket /opt/stack/data/neutron/lbaas/49717bc1-204c-42a8-9cc2-46db88a70365/sock mode 0666 level user defaults log global retries 3 option redispatch timeout connect 5000 timeout client 50000 timeout server 50000 frontend 8b1d4cd6-c07f-4b61-996b-8e72fb830eb9 option tcplog bind 10.0.0.23:80 mode http default_backend 49717bc1-204c-42a8-9cc2-46db88a70365 option forwardfor backend 49717bc1-204c-42a8-9cc2-46db88a70365 mode http balance roundrobin option forwardfor server 4668dae7-3259-4e2c-9e9e-870d50e8ded6 10.0.0.20:80 weight 1 server 90f9f52b-ea36-4dfc-b9bc-c1d43a8310e5 10.0.0.21:80 weight 5 server 913ccb64-7034-4295-8c73-44b3d904b775 10.0.0.22:80 weight 1 |
Bingo!
参考资料
- Network connectivity for physical hosts – OpenStack Cloud Administrator Guide
- Tenant and provider networks – OpenStack Cloud Administrator Guide
- Open vSwitch – OpenStack Cloud Administrator Guide
- Neutron Networking: VLAN Provider Networks
- Neutron Networking: Neutron Routers and the L3 Agent
- Tunnels as a Connectivity and Segmentation Solution for Virtualized Networks – FOSDEM ’14
- GRE Tunnels in OpenStack Neutron
- OpenStack Networking (Neutron) – 2014 Update