[转]Linux进程调度:CFS调度器的设计框架
一直计划要写一篇Linux内核中关于进程调度的文章,拖欠了很久,准备动手写的时候发现了此文,看过以后觉得着实没有自己重新写的必要了,转载于此。
一直计划要写一篇Linux内核中关于进程调度的文章,拖欠了很久,准备动手写的时候发现了此文,看过以后觉得着实没有自己重新写的必要了,转载于此。
有向图强连通分支算是个基础算法,不过总是忘记,写下来备忘。
无向图强连通分支非常简单,使用图的遍历算法(DFS或BFS)即可,而有向图的强连通分支计算则要复杂一些,Kosaraju’s algorithm实现了$O(n+m)$时间复杂度的有向图强连通分支算法。
算法的核心思想在于:从有向图中任何一个点出发做DFS,必然能从图中“拖”出一个点集,和无向图中不同的是,这个点集不一定构成强连通分支,但是如果我们能通过一个合适的顺序进行DFS(“sink” vertex),则可以依次把每一个强连通分支“拖”出来,得到正确的结果,那么算法的要点则在于如何寻找这个合适的顺序。
提到无向图的最小割问题,首先想到的就是Ford-Fulkerson算法解s-t最小割,通过Edmonds–Karp实现可以在$O(nm^2)$时间内解决这个问题($n$为图中的顶点数,$m$为图中的边数)。
但是全局最小割和s-t最小割不同,并没有给定的指定的源点s和汇点t,如果通过Ford-Fulkerson算法来解这一问题,则需要枚举汇点t(共$n-1$),时间复杂度为$O\left(n^2m^2\right)$。
Can we do better?
写这篇小结的时候,Ng的课程已经结束了(期待SoA哈哈哈),回顾整个课程内容,虽然Ng有意的屏蔽了大部分的数学内容,但是提纲挈领的为我们展现了常见机器学习算法的基本容貌和应用技巧,令人受益良多。从视频、课后问答到编程作业,都完美的示范了一门在线课程应该是什么样子的,不能感谢更多。
回到正题,异常检测,也称为离群点检测,是用来发现一些特征不同于预期的样本,在应用中具有极高的价值。异常检测有多种方法,Ng课程中讲的是基于统计学方法(高斯模型)的异常检测。
因为项目关系,接触学习了大名鼎鼎的Python网络编程框架Twised,Twisted是以高性能为目标的异步(event-driven)网络编程框架。

图中是Twisted官方推荐的学习书籍的封面,我觉得封面设计的非常贴切:Twisted就是很多Python(蟒蛇)纠缠在一起。
很多人说Twisted太复杂了,不易于使用,而我并不这么认为。虽然代码流程和朴素的代码流程大相径庭,但复杂性源自于异步编程的思想,而Twisted通过优秀的封装已经极大了减轻了我们的工作量。如果你之前没有接触过异步编程模型,我认为从Twisted入手不失为一个很好的选择。
学习Twisted的最好方式就是阅读Twisted的最新官方指南,有详尽的解释和代码示例,网络上其他的教程都是浪费时间(包括本文,前提是如果本文算得上是教程的话…)。
主成分分析(PCA)是一种通常用来做数据降维的非监督学习算法,下图是数据降维的直观说明:
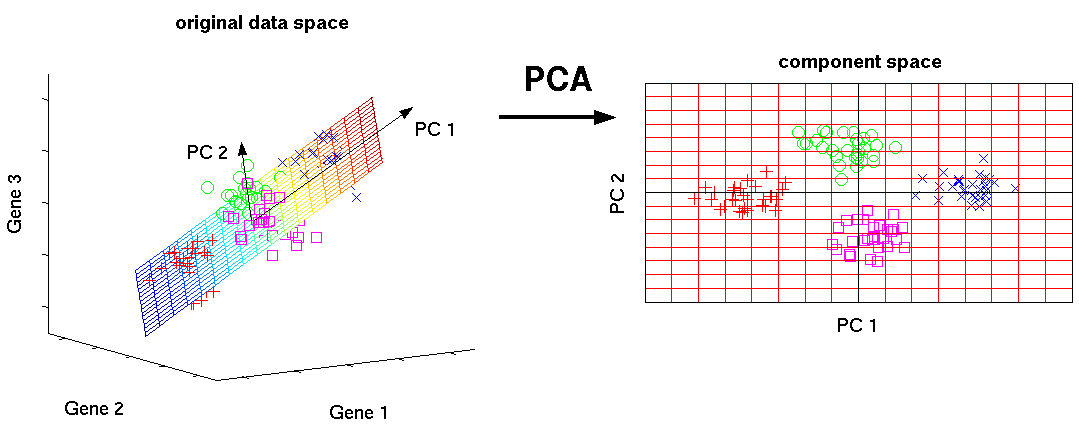
在PCA中,我们将每个样本看做特征线性空间中的一个向量,左图代表具有三个特征的样本(处于三维空间中,每个特征代表一个维度),通过寻找空间中样本的主成分PC1、PC2,以此建立新的二维线性空间来完成3D到2D的降维。
这已经是我第三次学习K-means算法了,K-means算法应该说不是一个复杂的算法,就做一个相对比较简单的记录吧。
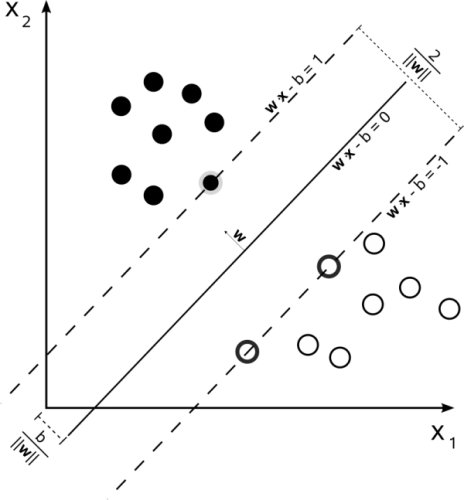
继续总结Ng的课程内容,这次是SVM。Ng在课程中说:
Most people consider the SVM to be the most powerful “black box” learning algorithm.
在实践中,SVM也的确是一种非常流行的“黑盒”学习算法,下图为SVM标志性的概念图:
一个非常常见的Python脚本如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
def main():
"""
main method for my test script~
"""
print sys.argv
if __name__ == '__main__':
main()
一直以来从来没考虑过为什么在脚本的第一行要写上 #!/usr/bin/env python 这样的注释,通常的解释是这样写就知道用什么来解释这个文件了,但是也没有深究为什么。其实这是一个Unix解释器文件的写法。

Linux内核中有很多同步机制,这篇文章主要总结一下在《Linux Kernel Development》看到的部分内核同步机制,依旧是备忘。
内核同步机制和用户空间的同步机制并不是一一对应的,但是基本的思想都是相同的:保护临界区,只是内核同步机制更适合于在解决内核中的同步问题。先思考下自己的Nanos内核中使用了什么同步机制?Nanos中使用了关中断和信号量机制。
Nanos中的信号量主要用来实现消息传递机制;lock()方法封装了基本的关中断操作,即通过关闭CPU中断(设置IF位)使得不会有线程切换发生,也就保护了临界区。但这在支持多核环境的内核中明显是不适用的,因为每个CPU都有自己的控制寄存器(eflags),关中断仅能保证当前CPU不会发生线程切换,而不能保证其他CPU上运行的线程不会进入临界区,因此,在Linux的SMP环境中需要更多粒度不同、开销不同的同步手段。
注:文中引用的Linux内核代码版本为2.6.32.63