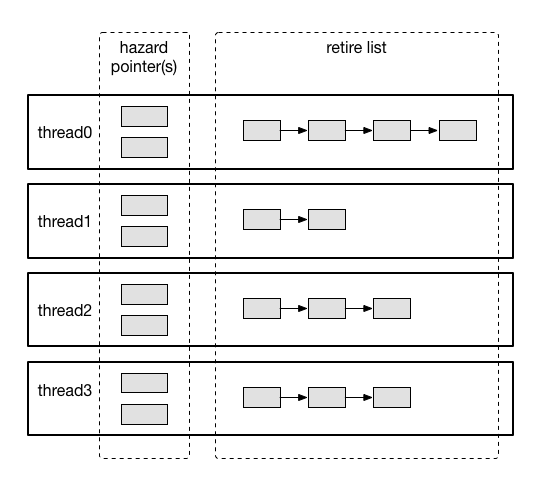
并发编程牛刀小试:SeqLock
Sequential lock,简称seq lock,是一种有点特殊的“读写锁”,Linux内核从2.6版本开始引入,是一种非常简单轻量保护共享数据读写的方法。
基本原理
Sequential lock的原理非常简单,其核心就是通过维护一个序号(sequence)来避免读者(Reader)读到错误的数据,而写者(Writer)在加锁和解锁的过程中递增序号,多个写者之间需要借助于额外的互斥锁来保证互斥关系。
具体来讲,序号初始化为0,读者和写者的流程如下:
- 写者开始修改临界区中的数据时,首先获取写者间互斥锁,然后递增序号(奇数),开始修改数据,修改数据完成后会再次递增序号(偶数),然后释放写者间互斥锁。
- 对读者来说,在修改数据的过程中读者可能会读到错误的数据,但读者在读数据前后会分别获取一次序号,对两次获取的序号进行比较,如果不相同则说明在读取过程中有写者进入了临界区,需要重试;如果序号相同但是是奇数,说明读者开始读取到结束读取的这段时间写者占有了临界区,同样也需要重试。
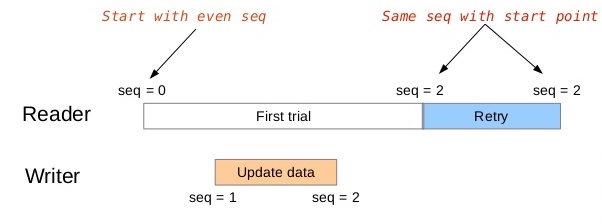
看个例子就明白了,如上图所示,是不是非常简洁明了。