用户态同步之自旋锁
最近花了一些时间研究如何在用户态实现自旋锁,这里简单的总结一下。本文的所有代码以及配套的测试用代码都可以在我的github上找到。
问题在哪
首先明确问题,我们需要一种用户态实现的线程同步机制,正确性当然是最重要的。本文的目的是实现正确的自旋锁(自旋锁比较简单轻量,但了解了原理后实现互斥锁并不困难,自行维护等待关系并通过 futex 对线程执行挂起、唤醒操作就可以了)。
概念上这个问题很简单啊,是不是我们只要用一个线程共享的变量做互斥,然后在线程获得和释放锁时修改这个变量就行了?比如像下面这样:
#ifndef _FAKELOCK_H_
#define _FAKELOCK_H_
class FakeLock
{
public:
FakeLock() {};
virtual ~FakeLock() {};
FakeLock(const FakeLock&) = delete;
FakeLock &operator=(const FakeLock&) = delete;
virtual int lock()
{
while (1L == lock_) {
asm volatile("pause\n" ::: "memory");
}
lock_ = 1L;
return 0;
}
virtual int unlock()
{
lock_ = 0L;
return 0;
}
private:
int64_t lock_;
};
#endif /* _FAKELOCK_H_ */
然而事情没这么简单,因为对这个变量的操作不是原子的,所以会导致这个锁无法正确的运行(即使在单核环境也如此),因此我们需要利用硬件提供的原子操作来实现锁(FYI. 一种不需要原子操作的锁实现方法见前文中提到过的Dekker算法,非常漂亮,但通用性不足)。
除此之外,另一个问题是多核争用的性能问题,这一点我会在后文中提到。
另外由于在用户态实现锁对硬件体系结构提供的一致性保证非常相关,所以必须注明,本文中所有实现针对于x86体系结构(也就是acquire-release语义TSO内存模型),不具备可移植性。
接口说明
为了后续说明方便,首先定义出自旋锁的接口:
#ifndef _LOCK_H_
#define _LOCK_H_
#include <stdio.h>
class BaseLock
{
public:
BaseLock() {};
virtual ~BaseLock() {};
BaseLock(const BaseLock&) = delete;
BaseLock &operator=(const BaseLock&) = delete;
virtual int lock() = 0;
virtual int unlock() = 0;
};
class BaseLockGuard
{
public:
BaseLockGuard(BaseLock &lock) : lock_(lock)
{
if (lock_.lock()) {
printf("lock failed.\n");
}
}
virtual ~BaseLockGuard()
{
if (lock_.unlock()) {
printf("unlock failed.\n");
}
}
BaseLockGuard(const BaseLockGuard&) = delete;
BaseLockGuard &operator=(const BaseLockGuard&) = delete;
private:
BaseLock &lock_;
};
#endif /* _LOCK_H_ */
后续的几种实现继承 BaseLock ,通过 lock 和 unlock 方法来进行加锁解锁操作。 BaseLockGuard 是RAII的资源管理类,可选。
TAS(test and set) lock
首先是最为基础的TAS lock,即利用test and set原子操作实现自旋锁。原理和我们上文看到的 FakeLock 是一样的,但是通过test and set把“读-写”的两个步骤原子化,保证了运行时的正确性。
#ifndef _TASLOCK_H_
#define _TASLOCK_H_
#include "lock.h"
class TASLock : public BaseLock
{
public:
TASLock() : lock_(0L)
{
}
virtual ~TASLock() override
{
}
virtual int lock() override
{
while (__sync_lock_test_and_set(&lock_, 1L)) {
asm volatile("pause\n");
}
return 0;
}
virtual int unlock() override
{
lock_ = 0L;
return 0;
}
private:
int64_t lock_;
};
#endif /* _TASLOCK_H_ */
这个锁效率很低,是因为没有引入引用指数退避之类的策略,等待效率低下,不过这不妨碍我们理解原理。在引入生产环境时需要注意这些细节。
Tiket lock
TAS lock存在的一个问题是公平性的问题,及等待在锁上的线程不是FIFO(先进先出)的,这可能会导致有些线程等待时间过长甚至饥饿。一般来说这并不是个好事情,于是有了一种保证FIFO的自旋锁:Tiket lock。(补充说明:FIFO的锁一定更好么?还是要分情况来看,FIFO的锁有可能性能更差,试想如果要获取锁的线程在锁空出来的时候恰好被调度出去了,那么其他所有线程都必须持续无意义的spin,导致了性能浪费。通过实验可以明显的看到当抢锁的线程数超过CPU核数时,FIFO的锁性能出现了明显的拐点)
Tiket lock的原理也十分简单:和我们在餐厅取号的原理相同,每一个尝试获取锁的线程都要先“取号”,然后等待“叫号”,解锁过程就是叫“下一个号”的过程,这样就保证了等待线程的FIFO。
#ifndef _TIKETLOCK_H_
#define _TIKETLOCK_H_
#include "lock.h"
class TiketLock : public BaseLock
{
public:
TiketLock() : next_tiket(0), now_serving(0)
{
}
virtual ~TiketLock() override
{
}
virtual int lock() override
{
int64_t my_tiket = __sync_fetch_and_add(&next_tiket, 1);
while (my_tiket != now_serving) {
asm volatile("pause\n" ::: "memory");
}
return 0;
}
virtual int unlock() override
{
now_serving += 1;
return 0;
}
private:
int64_t next_tiket, now_serving;
};
#endif /* _TIKETLOCK_H_ */
那Tiket lock还存在什么问题么?答案是多核并发的效率问题。不光是Tiket lock,前面的TAS lock也是一样,这两个锁的核心都是多线程同时访问一个变量,那么让我们回忆cache coherence的内容,这样的过程会引起大量的cache misses,以及必要的核间通信、cache line的争用。
如下图( unlock 过程中对 now_serving 的修改要invalidate其他核上的对应cache line):
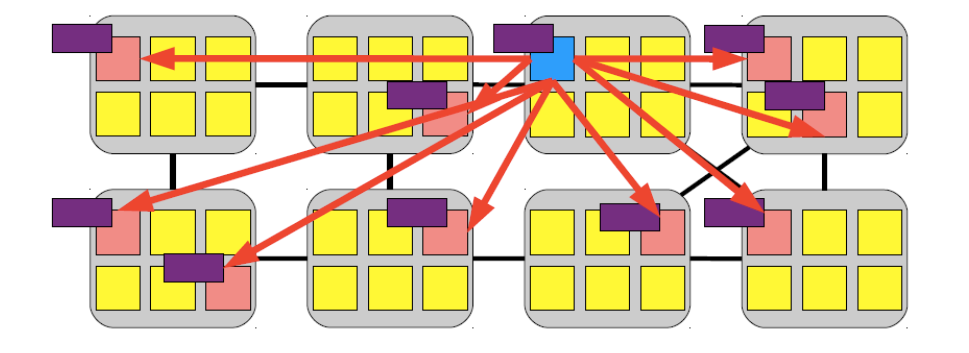
解决方法很简单,只要每个核都spin在自己持有的cache line中的变量上就可以了。后文中提到的几种锁的基本思想都是如此。
Array based queue lock
Array based queue lock,锁如其名,是基于数组实现的FIFO锁。使用数组代替单个变量来达到分离多核竞争的效果。
实现的原理是是当线程加锁时,找到锁的“等待队列”中上一个线程,spin在上一个线程的标记变量上,因为每个标记变量只被一个线程读取,所以减少了核之间的cache line争用。
#ifndef _ARRAYLOCK_H_
#define _ARRAYLOCK_H_
#include <utmpx.h>
#include <string.h>
#define CACHE_ALIGN_SIZE 64
#define CACHE_ALIGNED __attribute__((aligned(CACHE_ALIGN_SIZE)))
static const int64_t MAX_THREAD_NUM = 128;
class ArrayLock
{
public:
ArrayLock() : pack_(0L)
{
memset(slots_, 0L, sizeof(slots_));
pack_ = (unsigned long)&slots_[0] | 1Lu;
}
virtual ~ArrayLock() {}
ArrayLock(const ArrayLock&) = delete;
ArrayLock &operator=(const ArrayLock&) = delete;
virtual int lock(const int64_t tid)
{
if (tid < 0) return -1;
unsigned long pack = __sync_lock_test_and_set(&pack_, (unsigned long)&slots_[tid] | (unsigned long)slots_[tid].v);
bool *tail = &(((aligned_bool *)(pack & ~1Lu))->v);
bool locked = pack & 1Lu;
while (locked == *tail) {
asm volatile("pause\n" ::: "memory");
}
return 0;
}
virtual int unlock(const int64_t tid)
{
if (tid < 0) return -1;
slots_[tid].v = !slots_[tid].v;
return 0;
}
private:
struct aligned_bool{
bool v;
} CACHE_ALIGNED slots_[MAX_THREAD_NUM];
unsigned long pack_; // last bit is "this_means_locked"
};
class ArrayLockGuard
{
public:
ArrayLockGuard(ArrayLock &lock, const int64_t tid) : lock_(lock), tid_(tid)
{
if (lock_.lock(tid_)) {
printf("lock failed.\n");
}
}
virtual ~ArrayLockGuard()
{
if (lock_.unlock(tid_)) {
printf("unlock failed.\n");
}
}
ArrayLockGuard(const ArrayLockGuard&) = delete;
ArrayLockGuard &operator=(const ArrayLockGuard&) = delete;
private:
ArrayLock &lock_;
const int64_t tid_;
};
#endif /* _ARRAYLOCK_H_ */
代码实现比较繁琐,比较重要的一点是数组中每一个元素一定要按照cache line对齐。我的实现 tid 的处理不是很好。
基于数组的实现看似已经很完美了,唯有一个问题就是拓展性不好,受制于数组的动态伸缩能力有限,于是又有了下文中的两种基于链表的实现方法。
MCS lock
不论是基于链表还是基于数组,其基本思想依然是不变的:每一个核都等待在核局部的变量上。
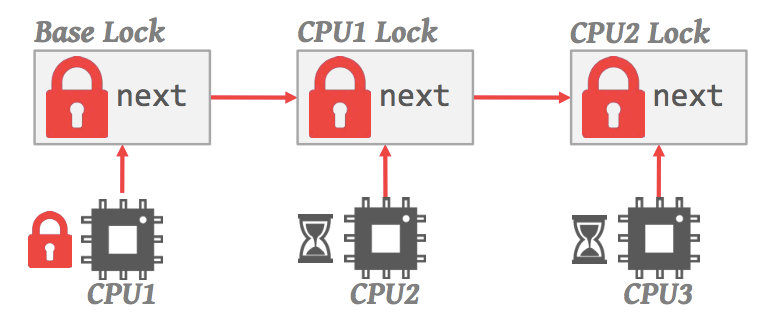
和数组不同的是当加锁时,需要提供一个链表节点(按cache line对齐),所以需要一个独特的基类中,基类定义了链表节点 qnode ,并重载了 new 和 delete 操作符,为了让申请到的内存按照cache line对齐:
#ifndef _LISTLOCK_H_
#define _LISTLOCK_H_
class ListLock
{
public:
class qnode
{
public:
qnode *p_qnode;
bool locked;
void *operator new(size_t request)
{
static const size_t needed = CACHE_ALIGN_SIZE + sizeof(void *) + sizeof(qnode);
void *alloc = ::operator new(needed);
void *ptr = (void *)((((unsigned long)alloc + CACHE_ALIGN_SIZE) & ~(CACHE_ALIGN_SIZE - 1)) + sizeof(void *));
((void **)ptr)[-1] = alloc; // save for delete calls to use
return ptr;
}
void operator delete(void *ptr)
{
if (ptr) { // 0 is valid, but a noop, so prevent passing negative memory
void * alloc = ((void **)ptr)[-1];
::operator delete (alloc);
}
}
};
ListLock() {};
virtual ~ListLock() {};
ListLock(const ListLock&) = delete;
ListLock &operator=(const ListLock&) = delete;
virtual int lock(qnode *node) = 0;
virtual int unlock(qnode *&node) = 0;
};
class ListLockGuard
{
public:
ListLockGuard(ListLock &lock) : lock_(lock)
{
node_ = new ListLock::qnode();
lock_.lock(node_);
}
virtual ~ListLockGuard()
{
lock_.unlock(node_);
delete node_;
}
ListLockGuard(const ListLockGuard&) = delete;
ListLockGuard &operator=(const ListLockGuard&) = delete;
private:
ListLock &lock_;
ListLock::qnode *node_;
};
#endif /* _LISTLOCK_H_ */
有了这个基类,让我们来实现大名鼎鼎的MCS lock。MCS lock的基本思想是:当一个线程离开临界区解锁时,通知队列中的下一个线程。
#ifndef _MCSLOCK_H_
#define _MCSLOCK_H_
#include "listlock.h"
class MCSLock : public ListLock
{
public:
MCSLock() : lock_(NULL)
{
}
virtual ~MCSLock()
{
}
virtual int lock(qnode *node) override
{
node->p_qnode = NULL;
qnode *prev = __sync_lock_test_and_set(&lock_, node);
// ATTENTION: time window here.
if (prev) {
node->locked = true;
prev->p_qnode = node;
while (node->locked) {
asm volatile("pause\n" ::: "memory");
}
}
return 0;
}
virtual int unlock(qnode *&node) override
{
if (!node->p_qnode) {
if (__sync_bool_compare_and_swap(&lock_, node, NULL)) {
return 0;
}
// take care of time window
while (!node->p_qnode) {
asm volatile("pause\n" ::: "memory");
}
}
node->p_qnode->locked = false;
return 0;
}
private:
qnode *lock_;
};
#endif /* _MCSLOCK_H_ */
CLH lock
另外一个基于链表的锁实现是CLH lock,基本上来说和MCS的做法如出一辙,区别在于MCS lock是解锁时通知队列中的下一个线程,而CLH lock是每个线程等待在队列中前一个线程的锁节点上(有点绕,代码上表现的很明显)。
#ifndef _CLHLOCK_H_
#define _CLHLOCK_H_
#include "listlock.h"
class CLHLock : public ListLock
{
public:
CLHLock()
{
lock_ = new qnode();
lock_->locked = false;
}
virtual ~CLHLock()
{
delete lock_;
}
virtual int lock(qnode *node) override
{
node->locked = true;
qnode *prev = __sync_lock_test_and_set(&lock_, node);
while (prev->locked) {
asm volatile("pause\n" ::: "memory");
}
return 0;
}
virtual int unlock(qnode *&node) override
{
qnode *t = node->p_qnode;
node->locked = false;
node = t;
return 0;
}
private:
qnode *lock_;
};
#endif /* _CLHLOCK_H_ */
其实代码上来看,CLH和MCS真的非常相似,如果硬要对比,CLH似乎更为简洁和高效?
Comments