Hazard Pointer
上一篇文章中实现了一个lock-free的队列,但是有一个问题:内存无法被安全的回收。那么,这次就来把这缺失的一环补上:hazard pointer,一种lock-free对象的内存回收机制。
PS:因为hazard pointer完整代码略有些长,不适合贴在文章内部,完整代码可以在这里找到。
解决了什么问题
在并发编程中,当我们在操作共享的内存对象时,需要考虑到其他线程是否有可能也正在访问同一对象,如果要释放该内存对象时不考虑这个问题,会引发严重的后果(访问悬空指针)。
线程互斥方法是解决这个最简单最直接的方法,访问共享内存时加锁即可保证没有其他线程正在访问同一对象,也就可以安全的释放内存了。但是如果我们正在操作的是一种lock-free的数据结构,我们自然不能容忍在这个问题上使用互斥来解决,这样会破坏lock-free的特性(不管任何线程失败,其他线程都能继续运行),那么,我们就需要一种同样lock-free的方法来解决共享内存对象的回收问题,Hazard Pointer就是其中一种方法。
除了共享内存的回收问题之外,另一个在lock-free编程中不得不提到的就是大名鼎鼎ABA问题。依我的理解来看,ABA问题和内存回收问题是相关的,都是内存的生命周期管理问题。具体来说,内存回收问题解的是共享内存什么时候能安全的回收,而ABA问题解的是共享内存什么时候能被安全的重新使用。因此,Hazard Pointer也可以用来解决ABA问题。
和GC有什么区别?
一种你可能最为熟悉的解决内存回收问题的方案是GC(垃圾回收)。GC的确可以解决内存回收问题,也可以解决大部分的ABA问题(先释放后重用的使用模式),但是却不能解决所有的ABA问题。例如两个链表实现的栈,不断在两个栈之间交换节点(弹出到对面),这样做内存并没有被回收,但是却面临重用问题,有ABA风险。而Hazard Pointer可以结合数据结构解决这一问题。
和智能指针有什么区别?
另一种C++中常见的内存管理机制是智能指针,惭愧的是我对智能指针实践有限,只能谈谈粗浅的理解。智能指针也是用来解决内存回收问题的,其本质是自动引用计数,通过智能指针对象的复制和销毁来维护引用计数。但智能指针和Hazard Pointer所解决问题的场景有很大差别:智能指针并不是线程安全的(多线程访问同一智能指针),用时髦点的话说,智能指针是一个语法糖(让你写起来很爽,但其实没有解决什么问题)。
基本原理
在我看来,hazard pointer的原理真的非常简单直接,而且易于理解。
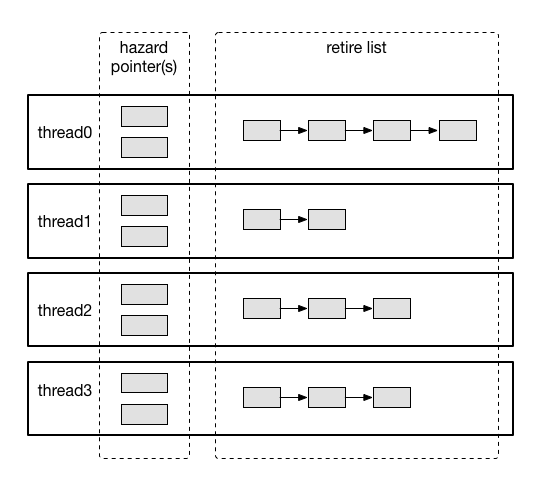
首先看看hazard pointer使用的数据存储结构。如题图所示,我们需要为每个线程准备一些线程局部的内存,用来存储两部分内容:
- pointers:用来存储这个线程当前正在访问的内存对象,正在访问的内存对象不能被任何线程释放
- retire list:被这个线程删除的内存对象,但还没有释放
既然我们需要安全的释放内存,那么hazard pointer的思路也很清晰:
- 每个线程都将自己正在访问且不希望被任何线程释放的内存对象存放在线程局部的pointers中
- 当任何线程删除内存对象后,都需要先把该内存对象放入自己线程局部的retire list
- 当retire list中的内存对象数量超过一定限度时,扫描retire list,找到没有被任何线程使用的内存节点并将其安全的释放
以上三步就构成了hazard pointer的全部内容。仔细分析流程会发现pointers是单写多读,而retire list是单写单读的,这个性质很重要,不然的话我们又需要另一种机制来保护hazard pointer了…
怎么用
hazard pointer的使用是要结合具体的数据结构的,我们需要分析所要保护的数据结构的每一步操作,找出需要保护的内存对象并使用hazard pointer替换普通指针对危险的内存访问进行保护。还是以上次的lock-free队列来说,使用了hazard pointer后代码变为下面的样子:
template <typename T>
void Queue<T>::enqueue(const T &data)
{
qnode *node = new qnode();
node->data = data;
node->next = NULL;
// qnode *t = NULL;
HazardPointer<qnode> t(hazard_mgr_);
qnode *next = NULL;
while (true) {
if (!t.acquire(&tail_)) {
continue;
}
next = t->next;
if (next) {
__sync_bool_compare_and_swap(&tail_, t, next);
continue;
}
if (__sync_bool_compare_and_swap(&t->next, NULL, node)) {
break;
}
}
__sync_bool_compare_and_swap(&tail_, t, node);
}
template <typename T>
bool Queue<T>::dequeue(T &data)
{
qnode *t = NULL;
// qnode *h = NULL;
HazardPointer<qnode> h(hazard_mgr_);
// qnode *next = NULL;
HazardPointer<qnode> next(hazard_mgr_);
while (true) {
if (!h.acquire(&head_)) {
continue;
}
t = tail_;
next.acquire(&h->next);
asm volatile("" ::: "memory");
if (head_ != h) {
continue;
}
if (!next) {
return false;
}
if (h == t) {
__sync_bool_compare_and_swap(&tail_, t, next);
continue;
}
data = next->data;
if (__sync_bool_compare_and_swap(&head_, h, next)) {
break;
}
}
/* h->next = (qnode *)1; // bad address, It's a trap! */
/* delete h; */
hazard_mgr_.retireNode(h);
return true;
}
不要纠结在具体的实现定义上,可以看到的是队列的基本算法是没有改变的(如果你不熟悉这个队列的实现,请参考我的上一篇文章),区别在于我们使用 HazardPointer 保护了几个运行中需要持续保护的指针,在队列这个数据结构中,同一线程最多需要保存两个pointer就够了。
在获取内存对象地址时,我们使用 HazardPointer::acquire 方法将要保护的内存对象放入到hazard pointer中,在删除节点后,我们将内存对象交给 retireNode 方法,由hazard pointer负责安全的释放对应内存。
正确性保证
hazard pointer的正确性在论文1中有非常完整的论述,我就挑其中一个我认为非常重要的点来解释为什么hazard pointer可以正确的工作。
考虑这种情况:
- 线程A开始访问内存对象o,拿到了o的地址
- 线程B将内存对象o从数据结构中删除,加入retire list,并扫描所有线程的pointers,此时线程A还没有来得及将o放入到pointers中,因此B可以将o释放
- 线程A将o放入pointers中
- 线程A访问o,crash…
看上去很危险,但实际上这种情况在hazard pointer中并不会发生,因为hazard pointer的正确性证明要求线程在pointers中持有的内存对象都必须是“连续安全的”,这是什么意思呢?简单来说,就是说从线程取到该内存对象的一刻开始到将其放入pointers的这段过程中这个内存对象不能被其他线程从数据结构中删除,也就是说其安全状态必须是“连续”的(安全指不会被释放,在数据结构中或是加入到pointers中的的内存对象都是安全的)。
这个要怎么做到呢?其实很简单:double check,代码如下:
template <typename T>
bool HazardPointer<T>::acquire(const T* const *node)
{
release();
node_ = *node;
if (!mgr_.acquire(node_, tid_)) {
return false;
}
// continuosly holding, need sequential consistency
__sync_synchronize();
if (*node != node_) {
release();
return false;
}
return true;
}
必须要特别注意这里要检查是对象是否还在数据结构中,上面的检查代码示例对一些使用场景是一个比较好用的简化封装,但不是一劳永逸的,比如前面的dequeue函数中第43行就需要做一个额外检查,这也是hazard point比较难用的一点。
于是流程变成了这样:
- 线程A开始访问内存对象o,拿到了o的地址
- 线程B将内存对象o从数据结构中删除,加入retire list,并扫描所有线程的pointers,此时线程A还没有来得及将o放入到pointers中,因此B可以将o释放
- 线程A将o放入pointers中
- 线程A对o执行double check,发现o已经不在数据结构中了(被删除),因此认为加入到pointers中的地址是无效的,撤销并失败退出
规避了这个问题,正确性证明的其他部分就非常容易理解了。
你可能注意到了我在代码中double check过程之前使用了内存屏障,这是因为此处必须避免可能发生的“写-读”乱序问题,一旦发生乱序,则double check将毫无意义,也就是说x86提供的acquire-release语义TSO内存模型不能满足hazard pointer的需求,我们需要更强的sequential consistency才行。
retire过程“优化”
另一个值得一提的点是对论文中对retire list执行扫描的过程可以做一点小小的“优化”:论文中的做法是先将所有线程的pointers组织成一个有序数组,然后在扫描retire list时对该数组做二分查找(时间复杂度为\(O(\log{n})\));实际实现中可以采用一个更加激进的方法,把所有线程的pointers无视冲突的哈希到一个布尔数组上,然后对retire list中的每个元素都可以以\(O(1)\)的时间复杂度确认是否可以被释放,代码如下:
void HazardManager::scan(threadlocal &rdata)
{
rnode *p = rdata.rlist;
rnode *q = p->next;
bool map[hash_size_];
memset(map, 0, hash_size_);
for (int64_t i = 0; i < MAX_THREAD_NUM; ++i) {
const threadlocal &data = storage_[i];
for (int64_t j = 0; j < data.pcount; ++j) {
map[(unsigned long)data.hp[j] & hash_mask_] = true;
}
}
while (q) {
// scan and free
if (!map[(unsigned long)q->node & hash_mask_]) {
const rnode *t = q;
q = q->next;
p->next = q;
rdata.rcount--;
delete t->node; // bad design...
delete t;
} else {
p = q;
q = p->next;
}
}
}
那么这样的做法为什么是正确的呢?因为即使哈希产生了冲撞,所造成的后果无非是一个本可以释放的对象无法立刻被释放(但最终一定会被释放),而绝不会产生一个不能被释放的对象被判断为可以安全释放的情况。这样,我们以稍微延迟一些对象内存释放的代价加速了整个扫描过程,何乐而不为呢?
其他方法
Hazard Pointer虽然很好,但并不是解决这一问题的唯一方法。McKenney在论文2中将这类算法分为两类:阻塞和非阻塞的(McKenney只讨论lockless的概念,lockfree算法属于其中非阻塞类)。
阻塞算法的代表是Quiescent-State-Based Reclamation(QSBR),Linux内核中广泛使用的RCU(read-copy-update)就属于此类(之后可能也会写篇文章介绍?);非阻塞算法的代表就是本文所描述的Hazard Pointer,以及Lock-Free Reference Counting。
McKenney作为RCU维护者,必然要指出Hazard Pointer的痛处:需要的内存屏障多(每次aquire都要触发一次),要求sequential consistency,而内存屏障的性能开销是比较高的。但McKenney作为利益相关者,我对其结论持怀疑态度。
参考资料
-
Michael M M. Hazard pointers: Safe memory reclamation for lock-free objects[J]. IEEE Transactions on Parallel and Distributed Systems, 2004, 15(6): 491-504. ↩
-
Hart T E, McKenney P E, Brown A D. Making lockless synchronization fast: Performance implications of memory reclamation[C]//Parallel and Distributed Processing Symposium, 2006. IPDPS 2006. 20th International. IEEE, 2006: 10 pp. ↩
Comments